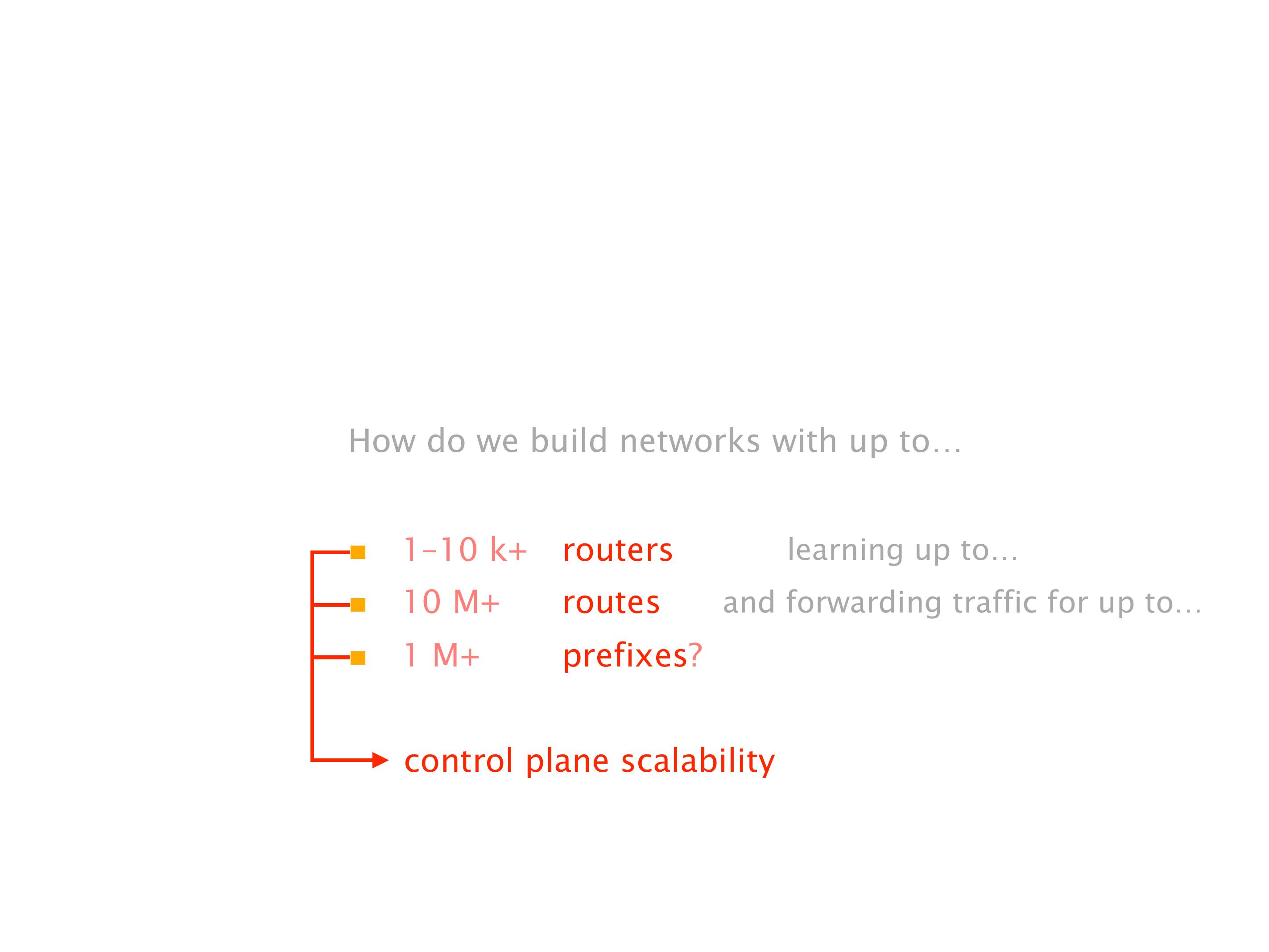
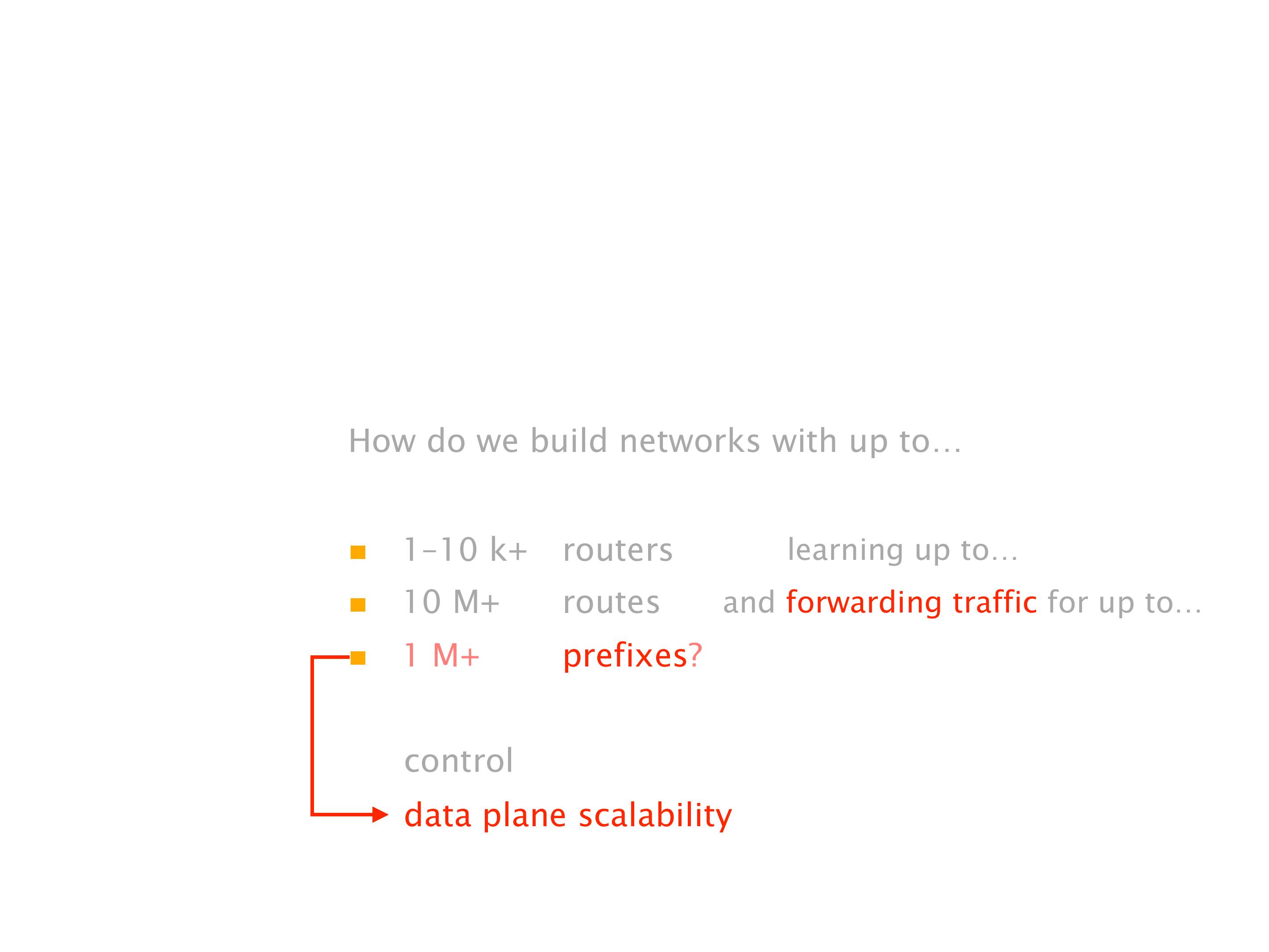
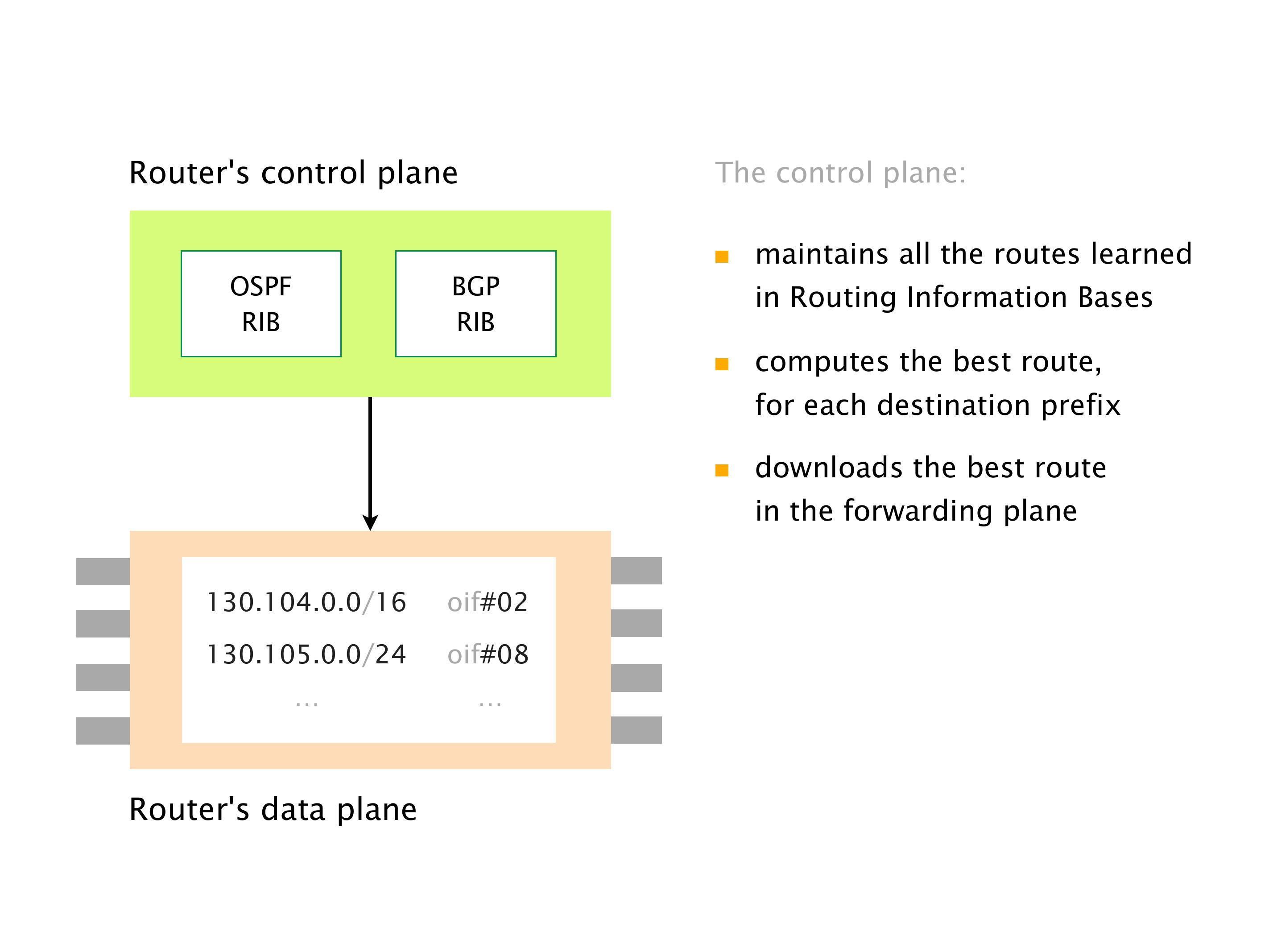
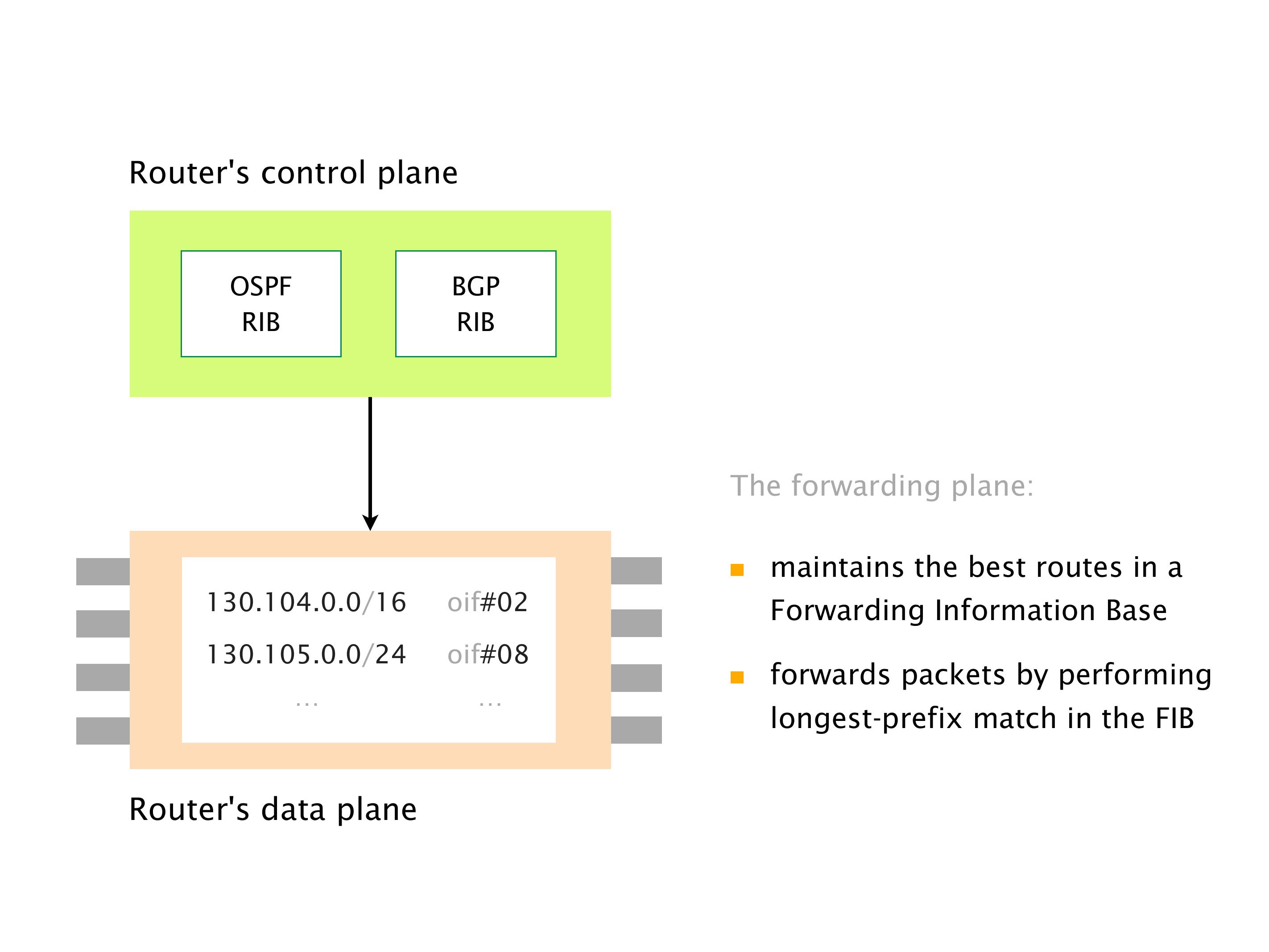
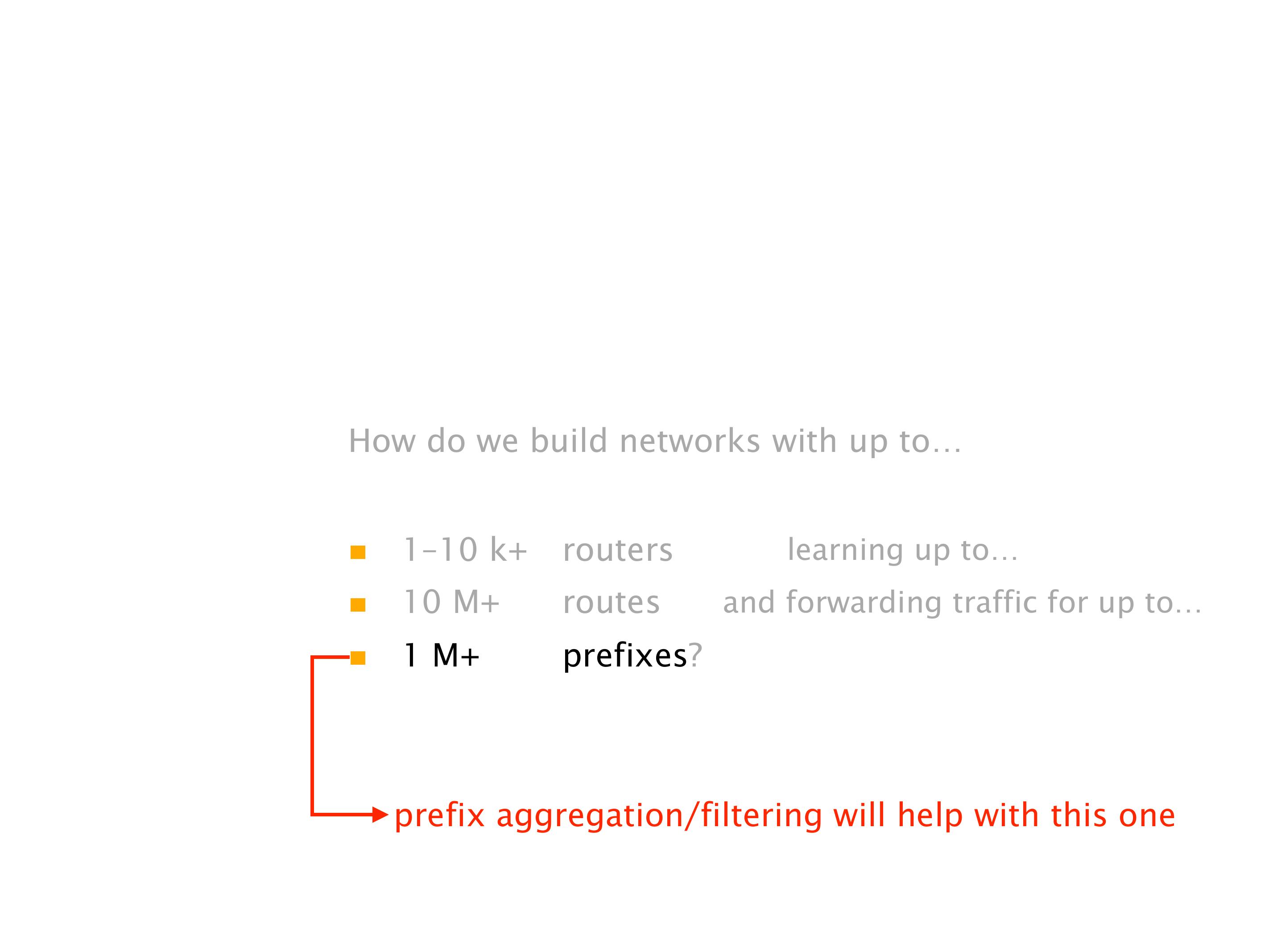
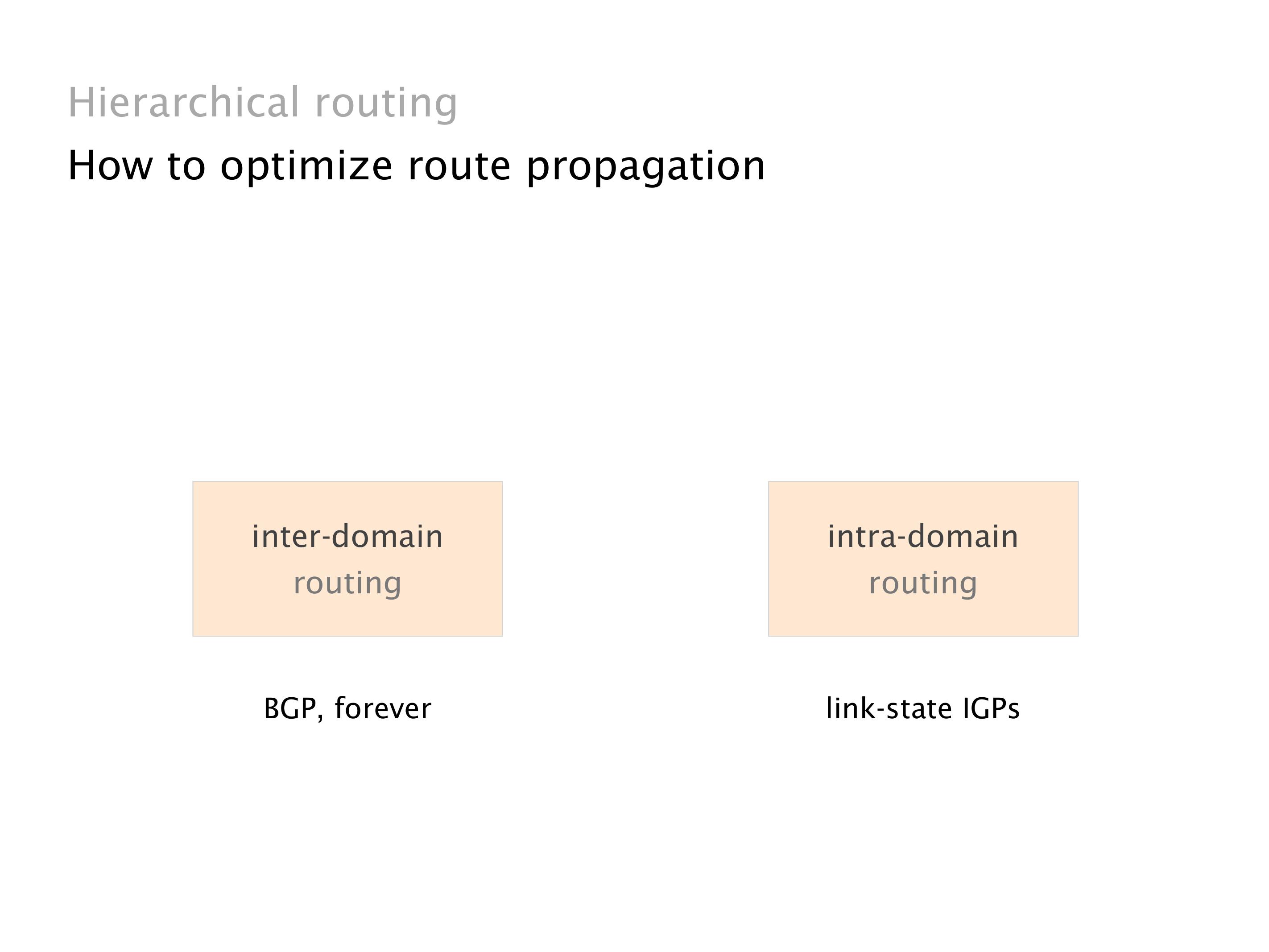
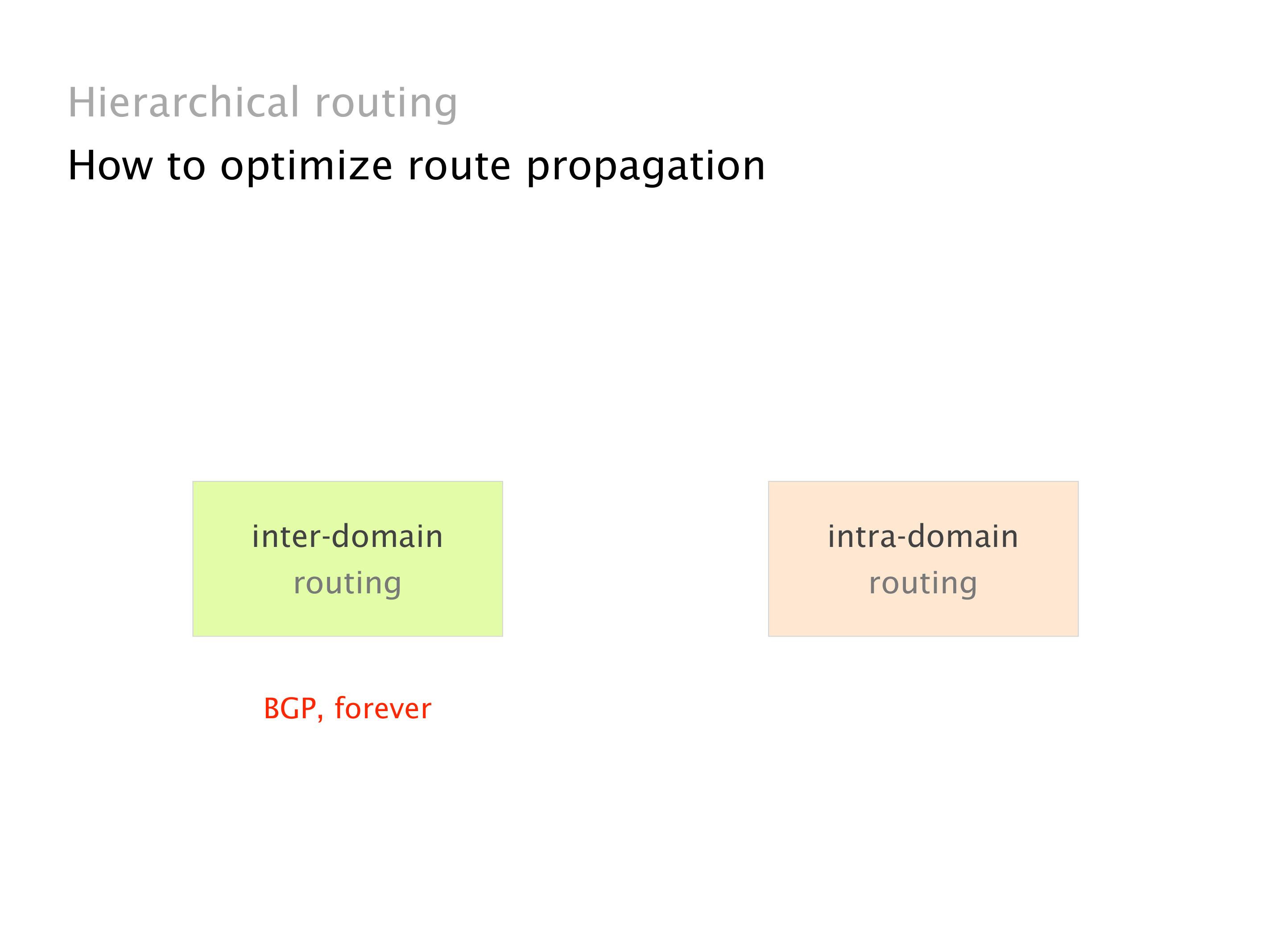
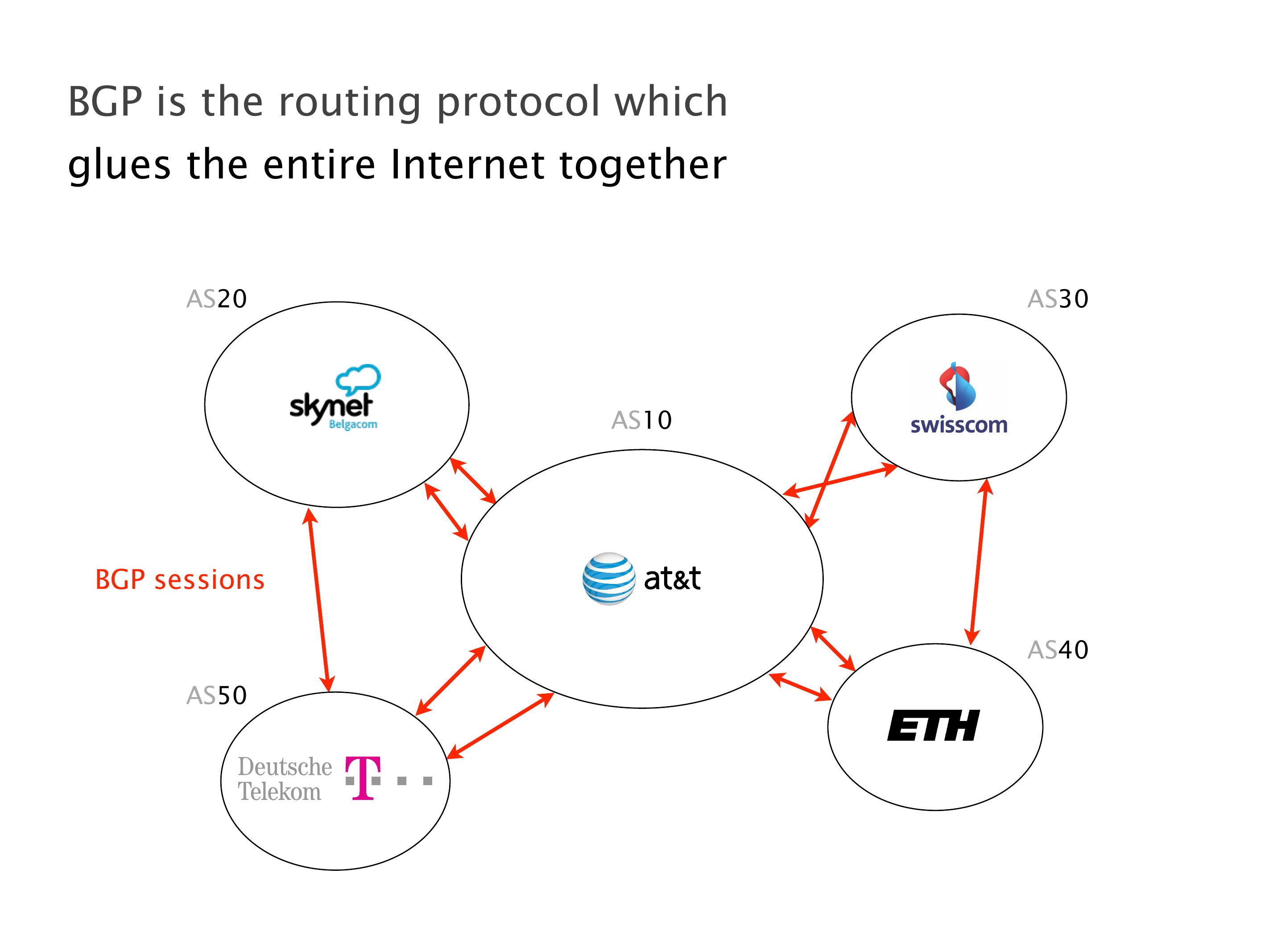
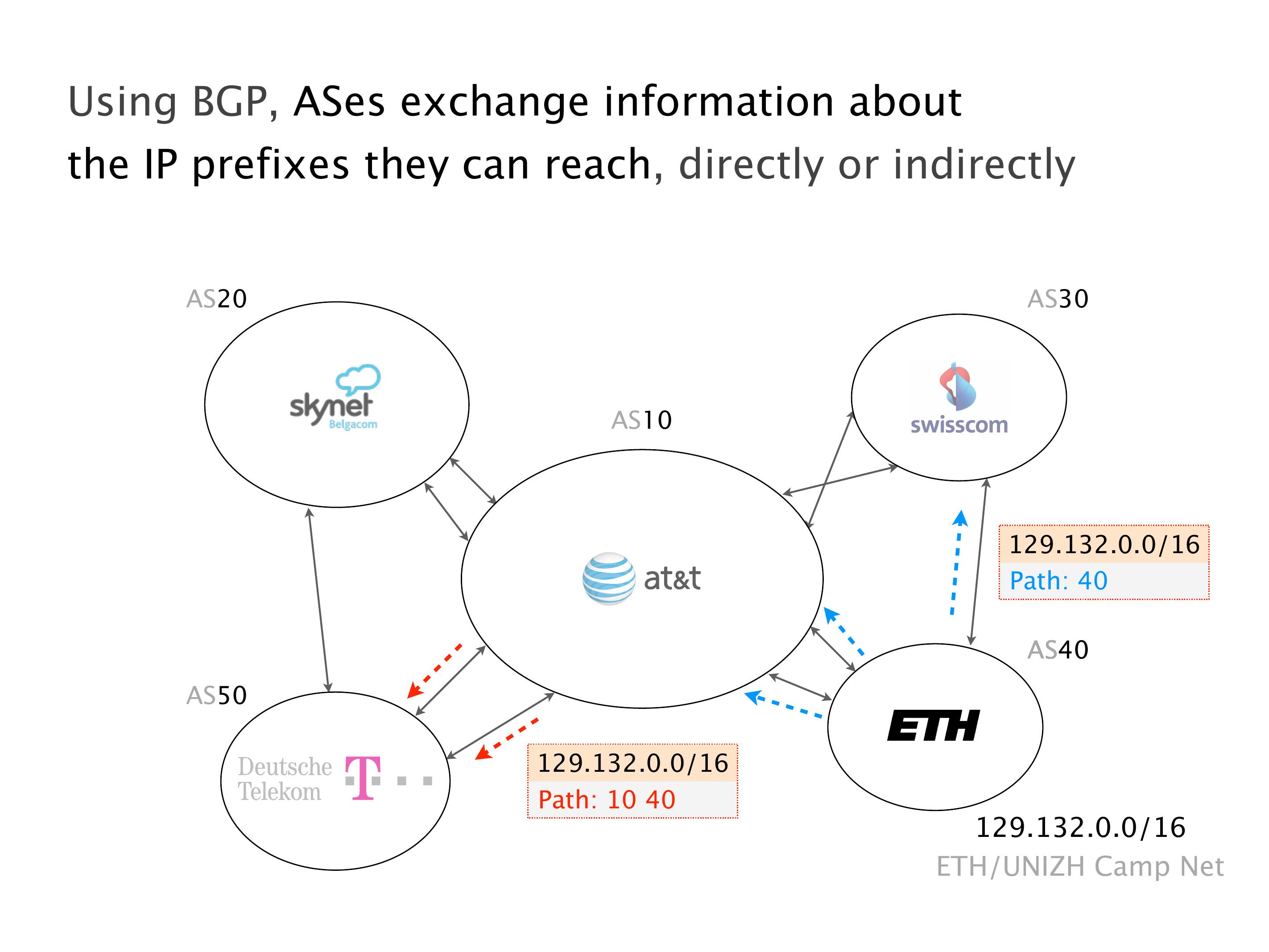
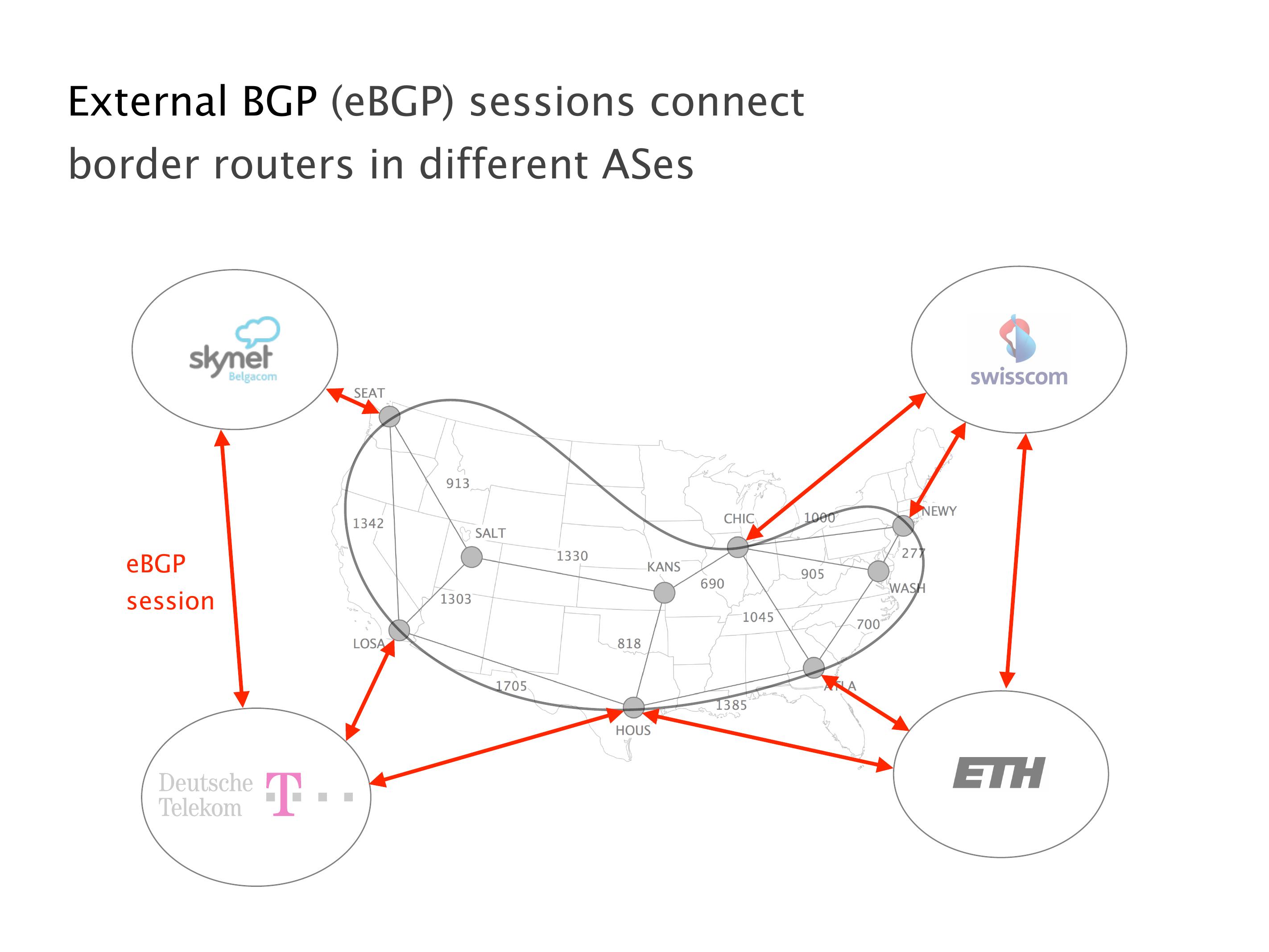
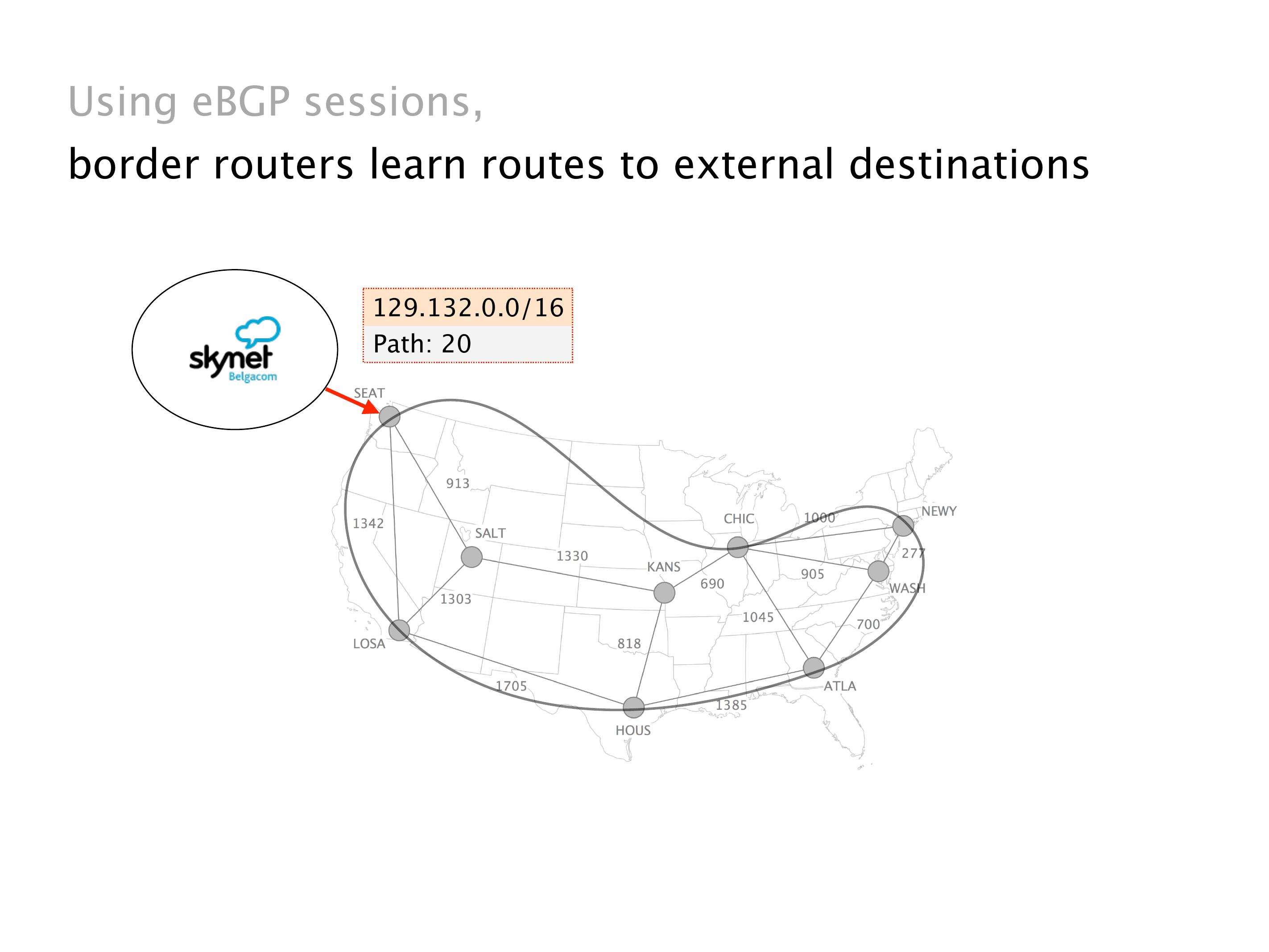
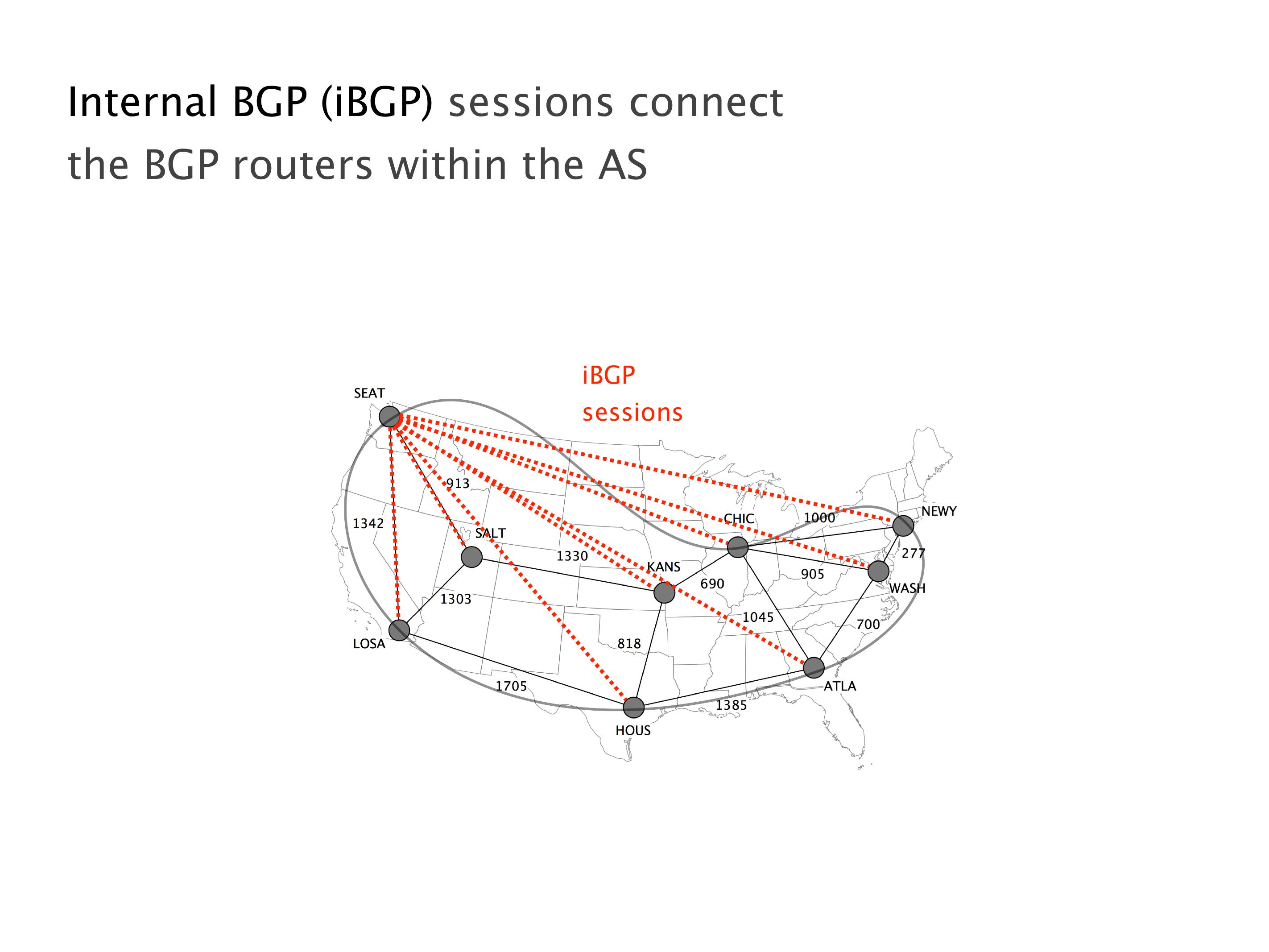
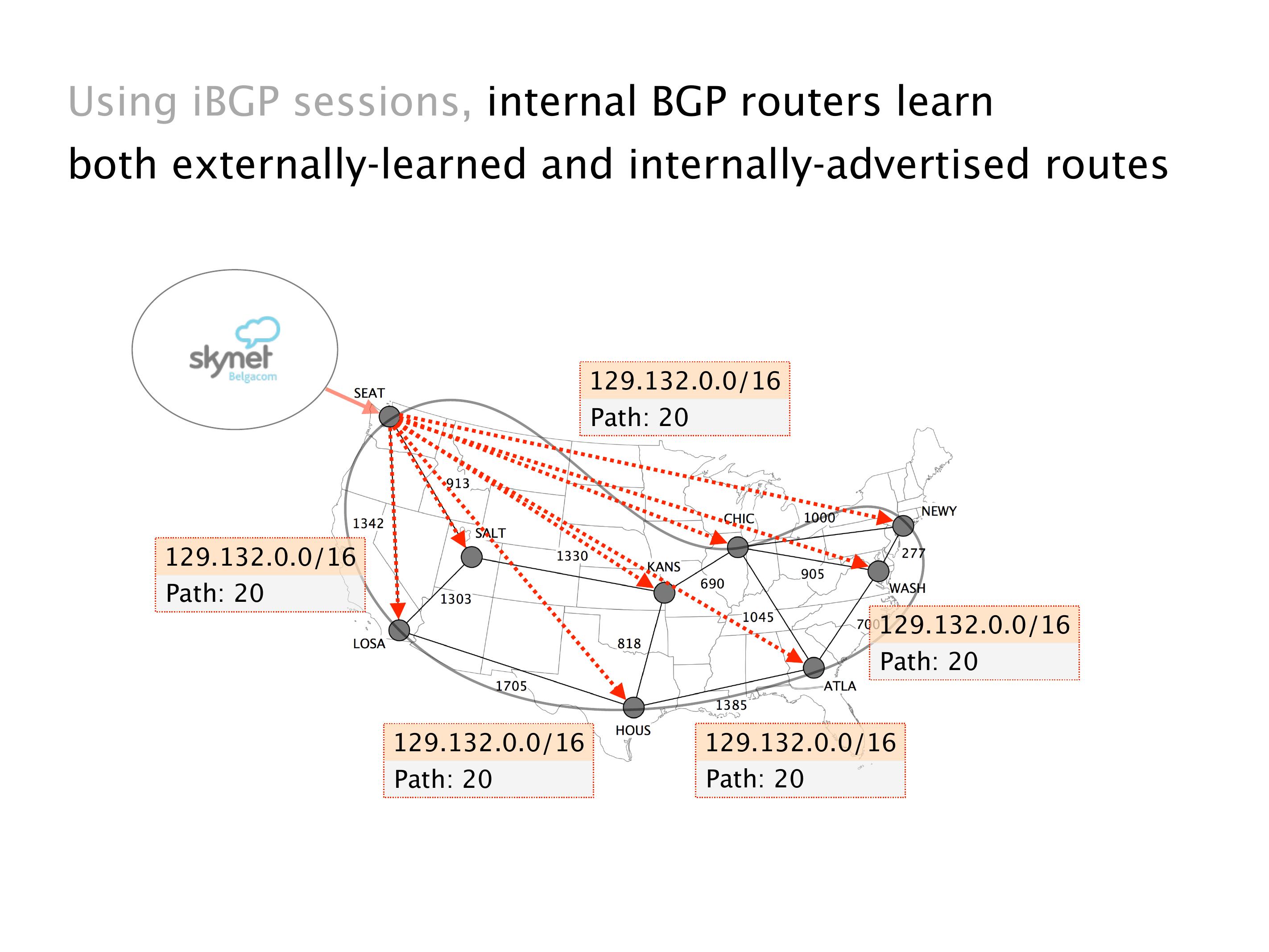
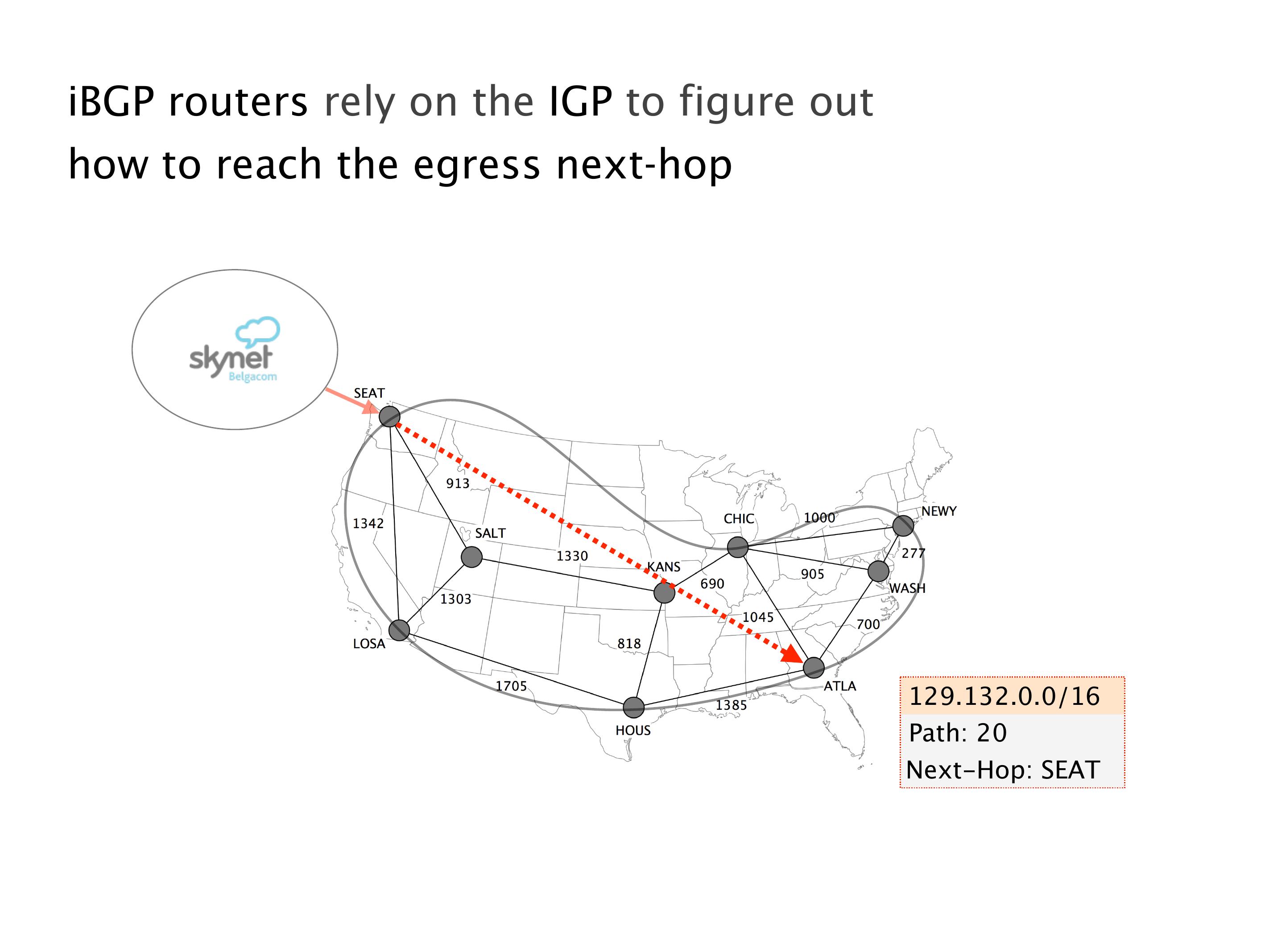
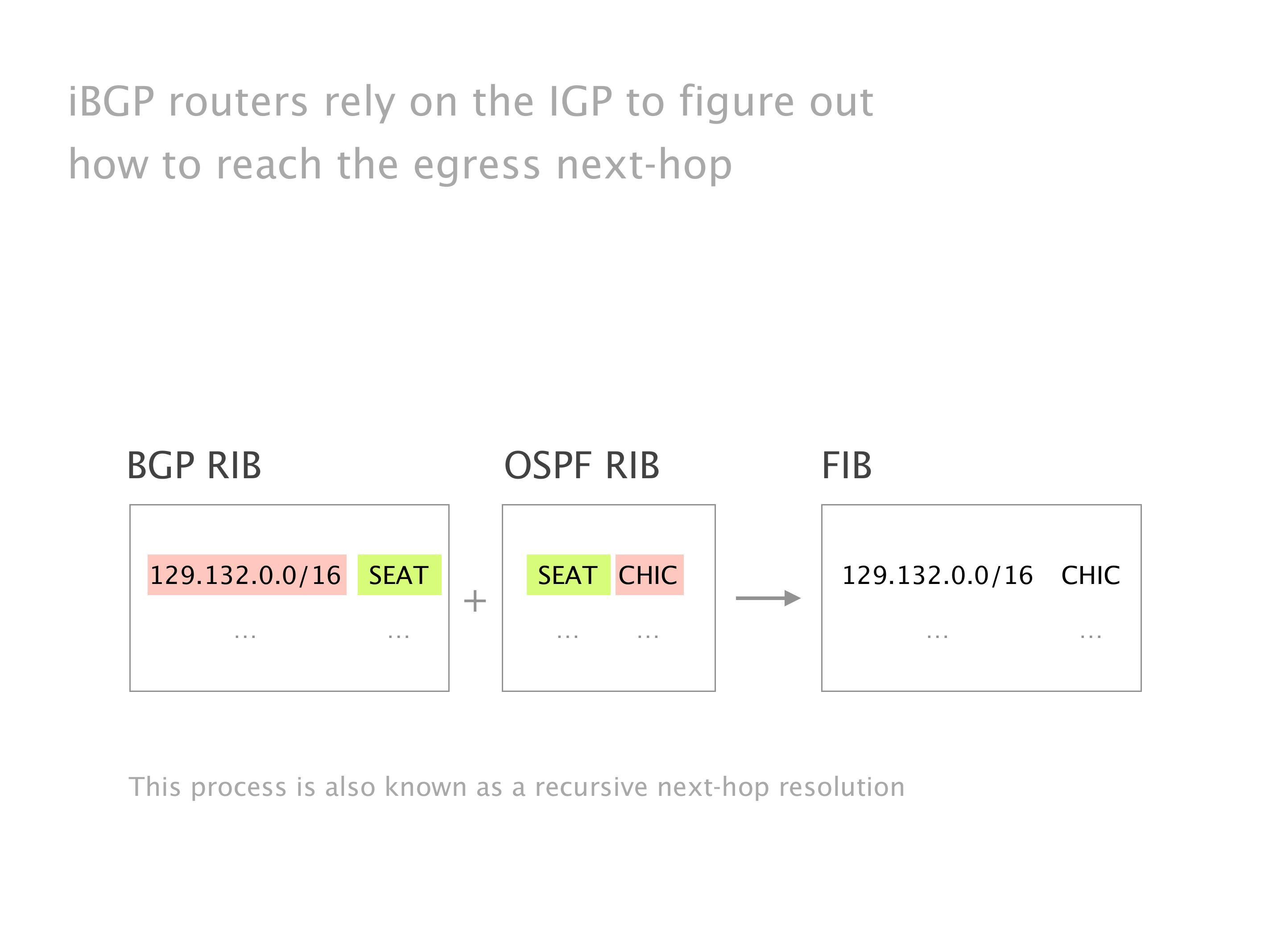
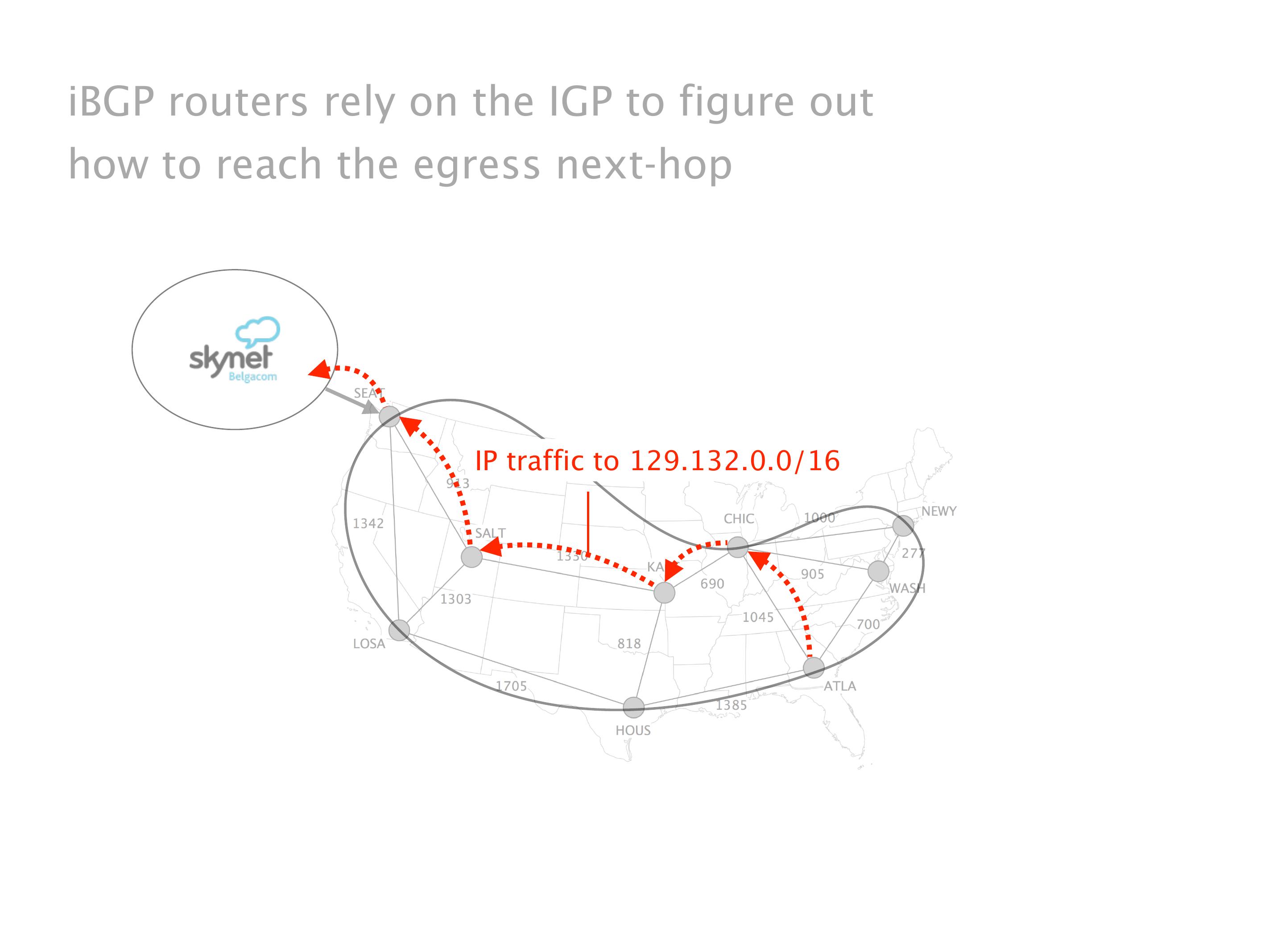
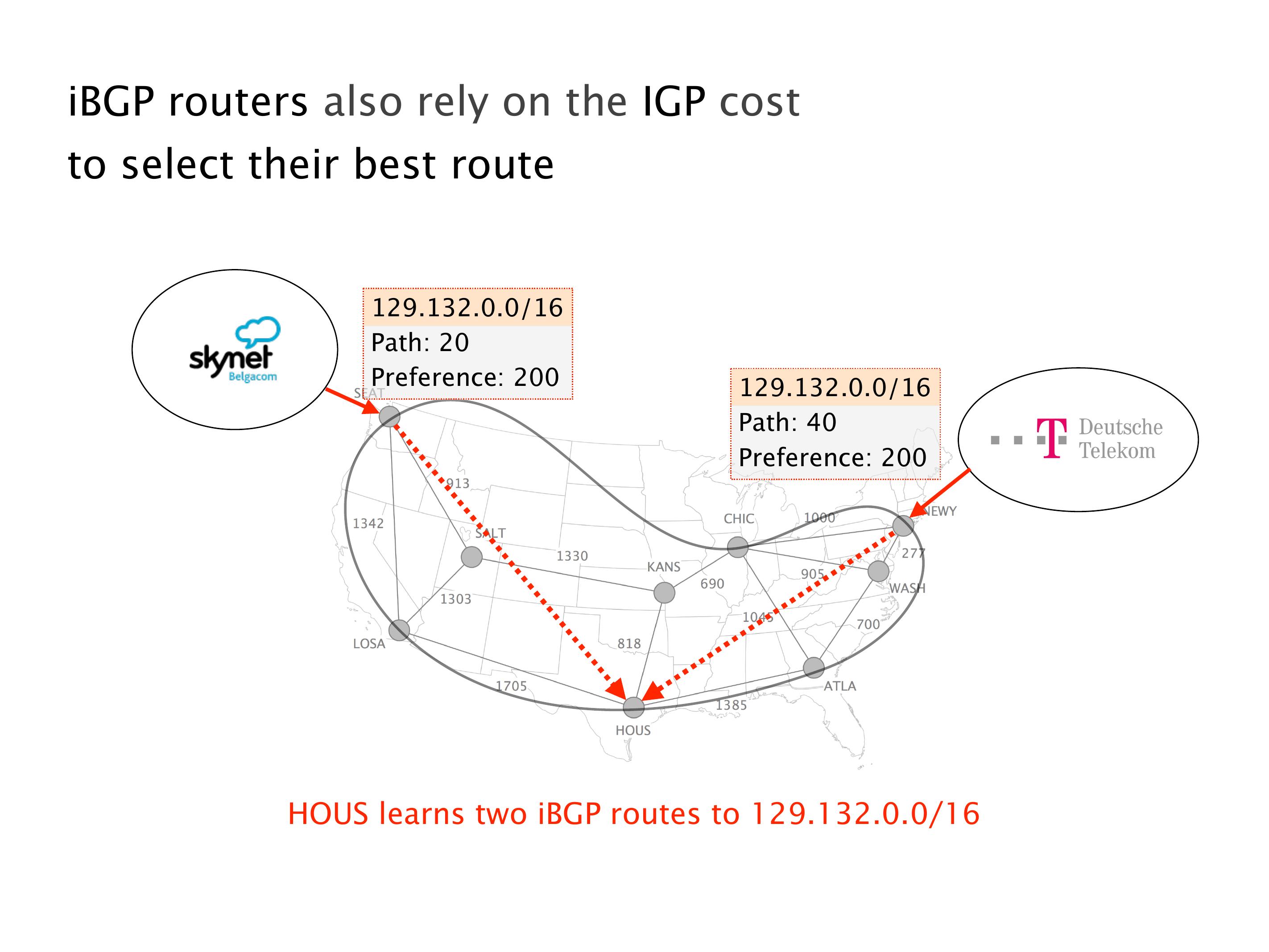
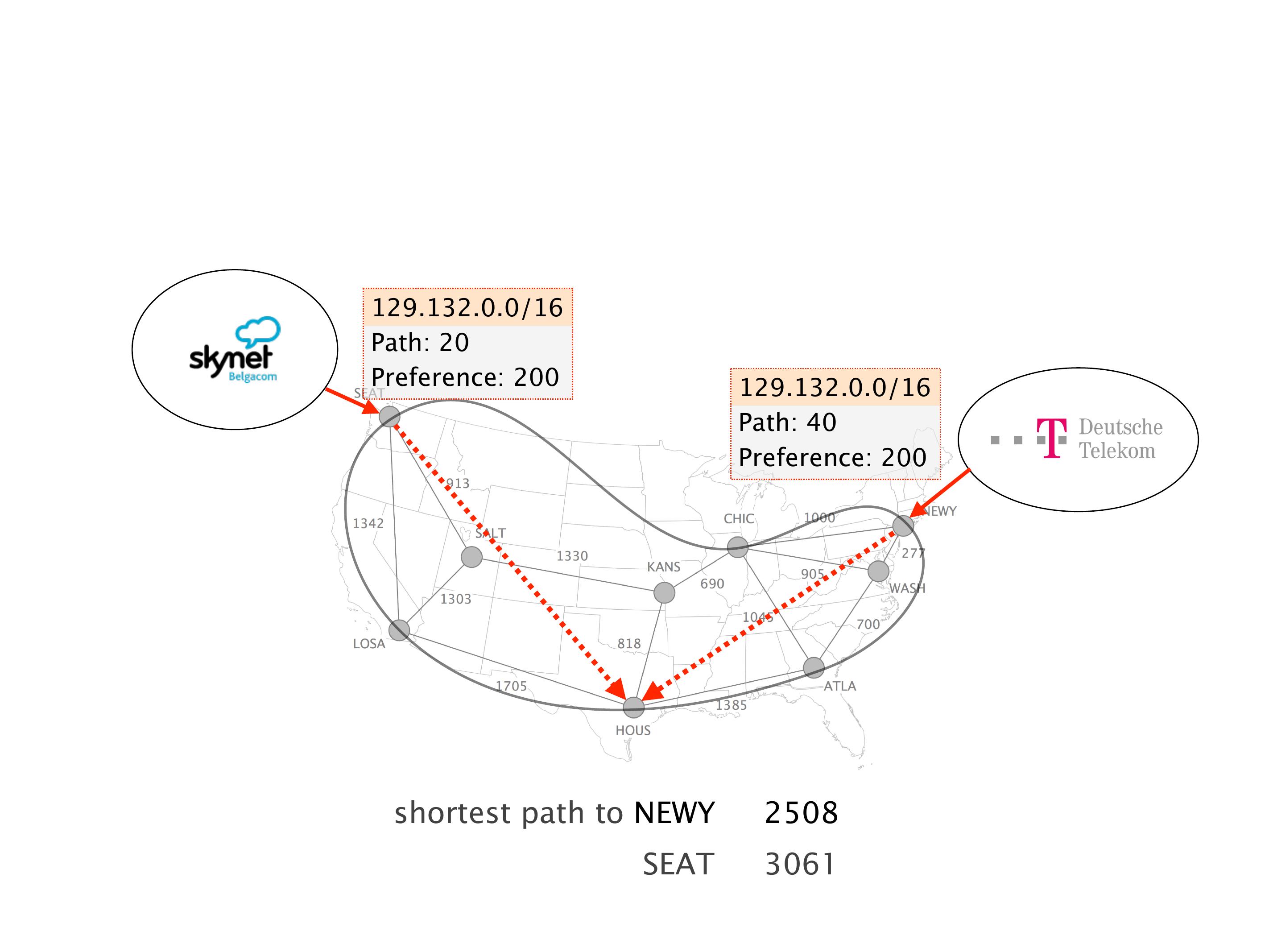
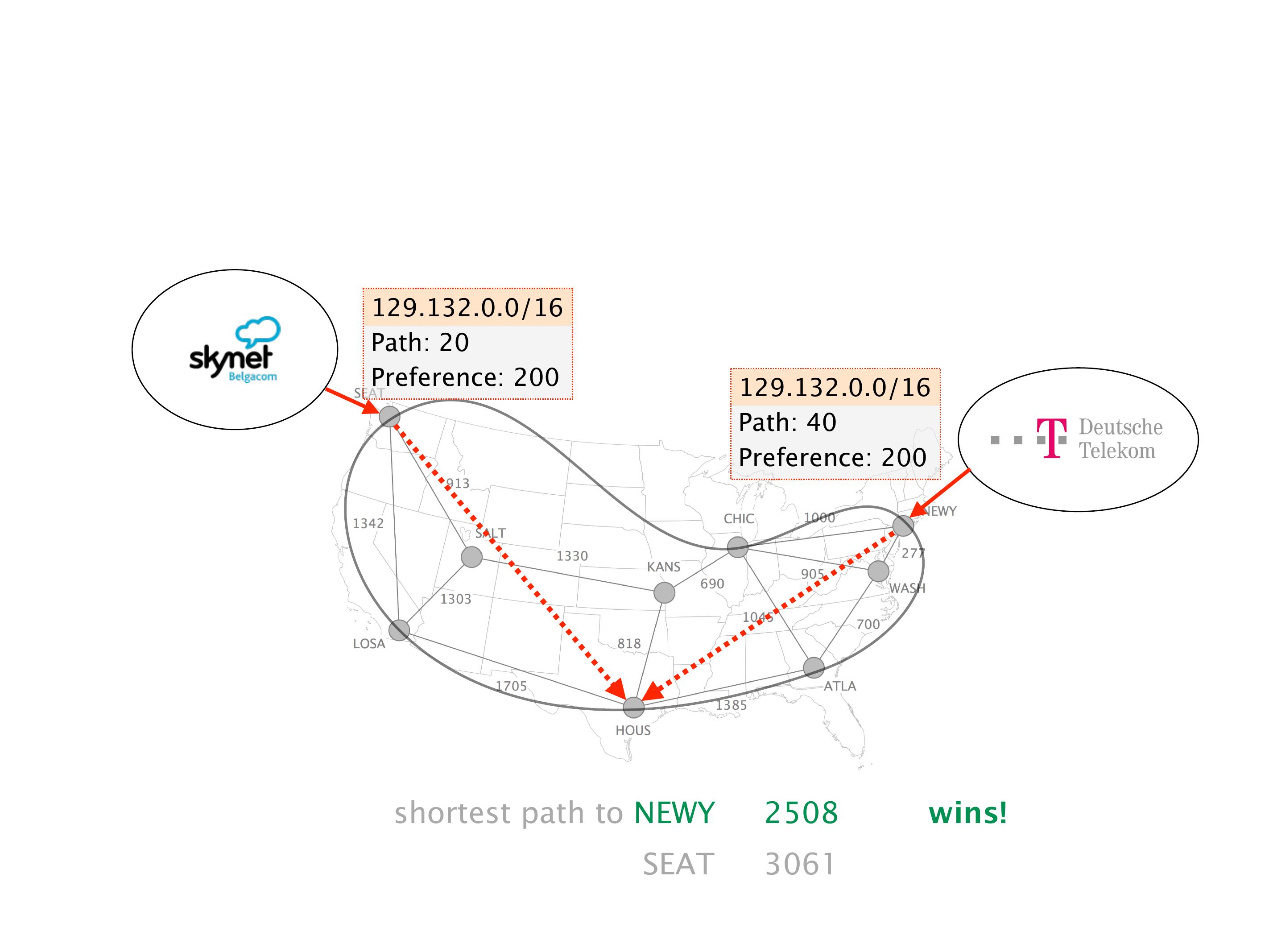
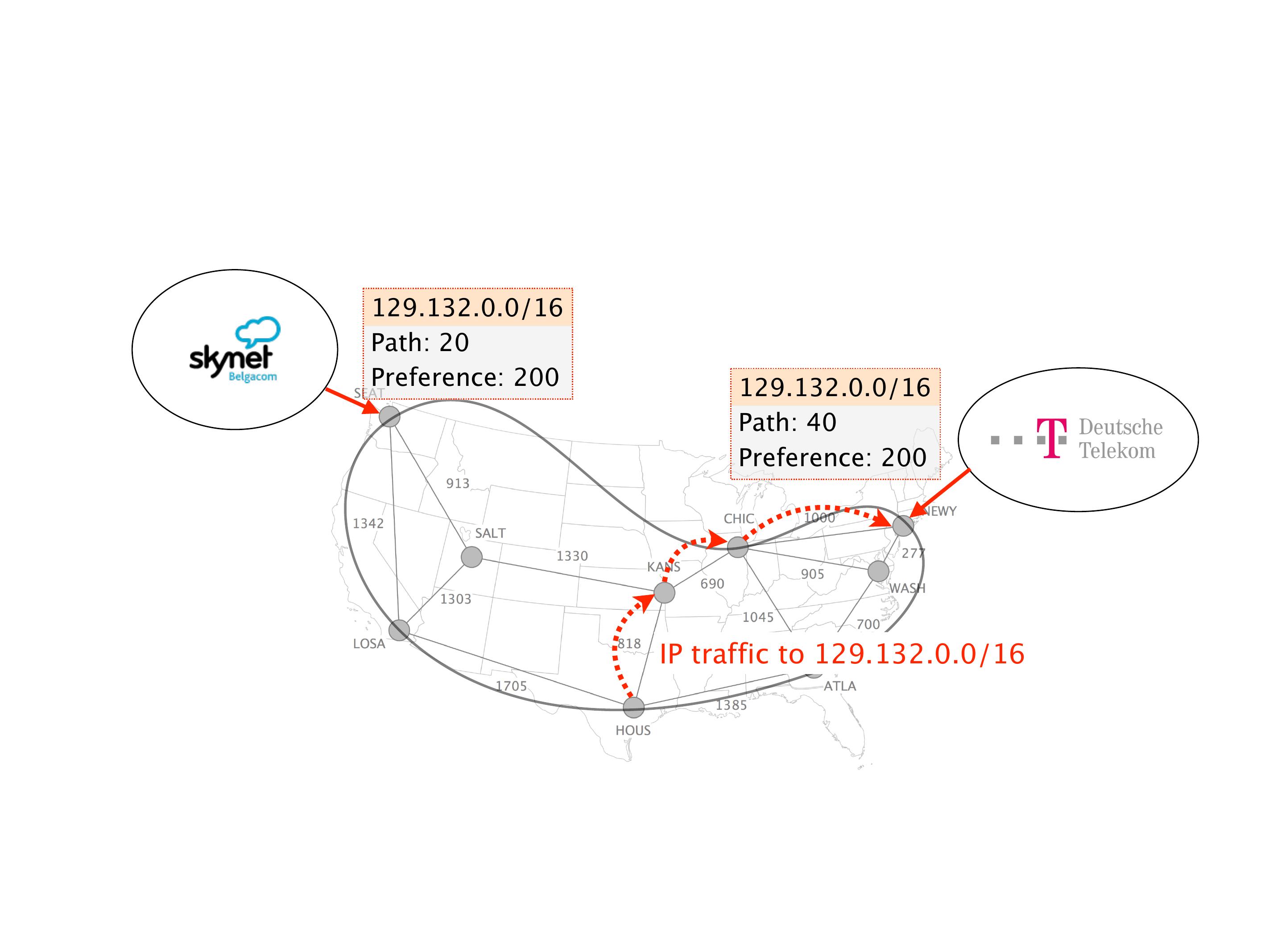
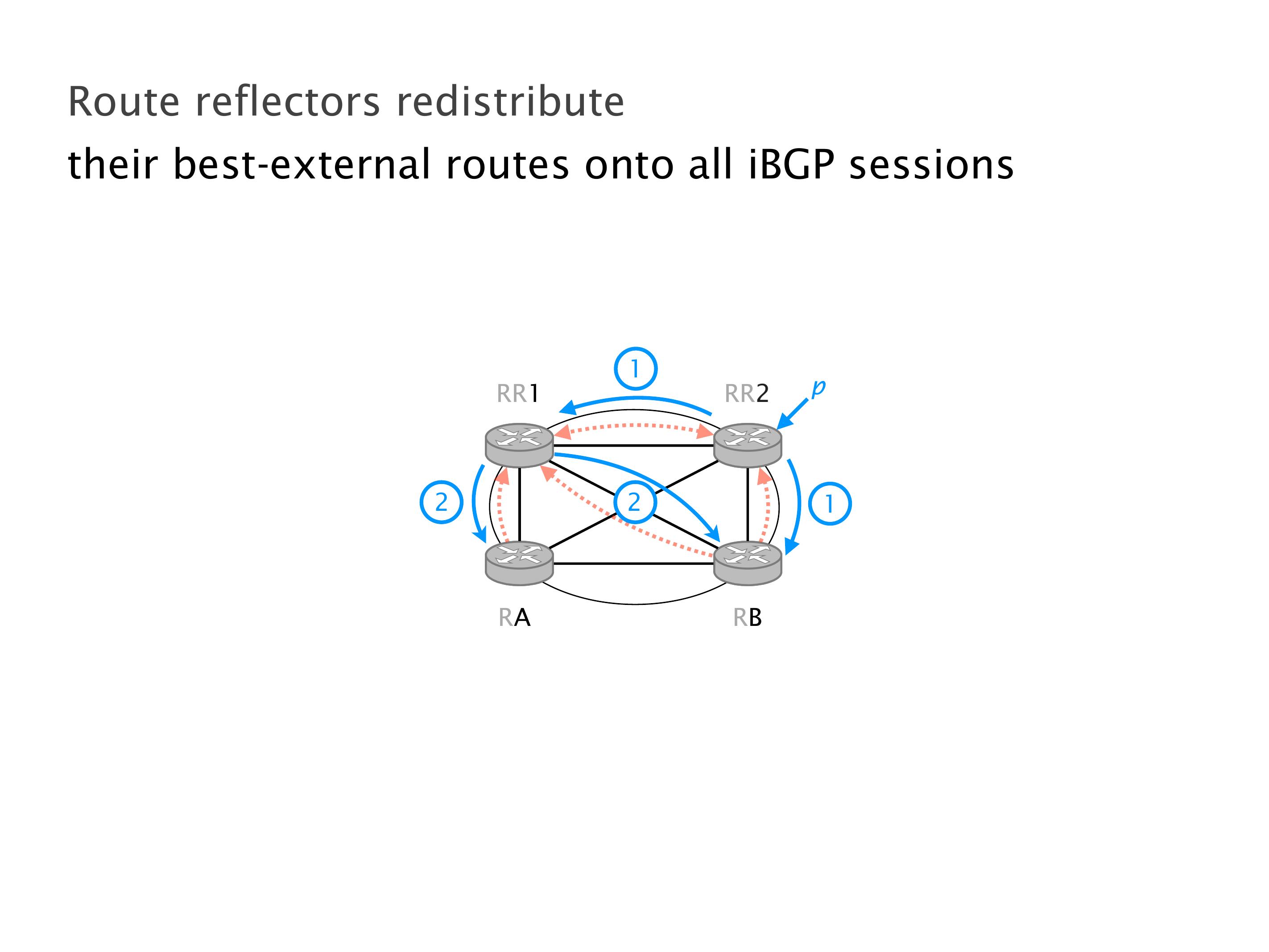
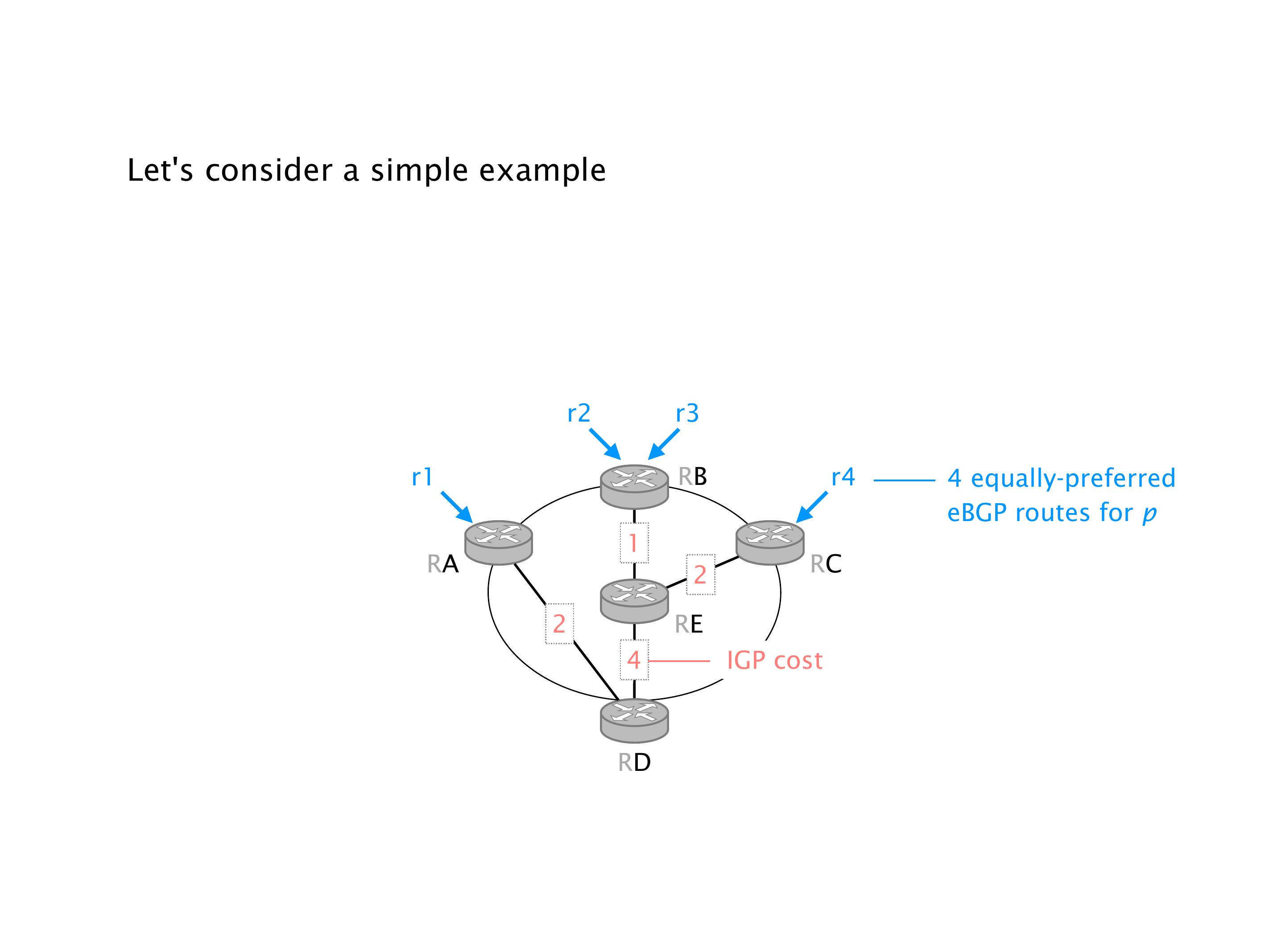
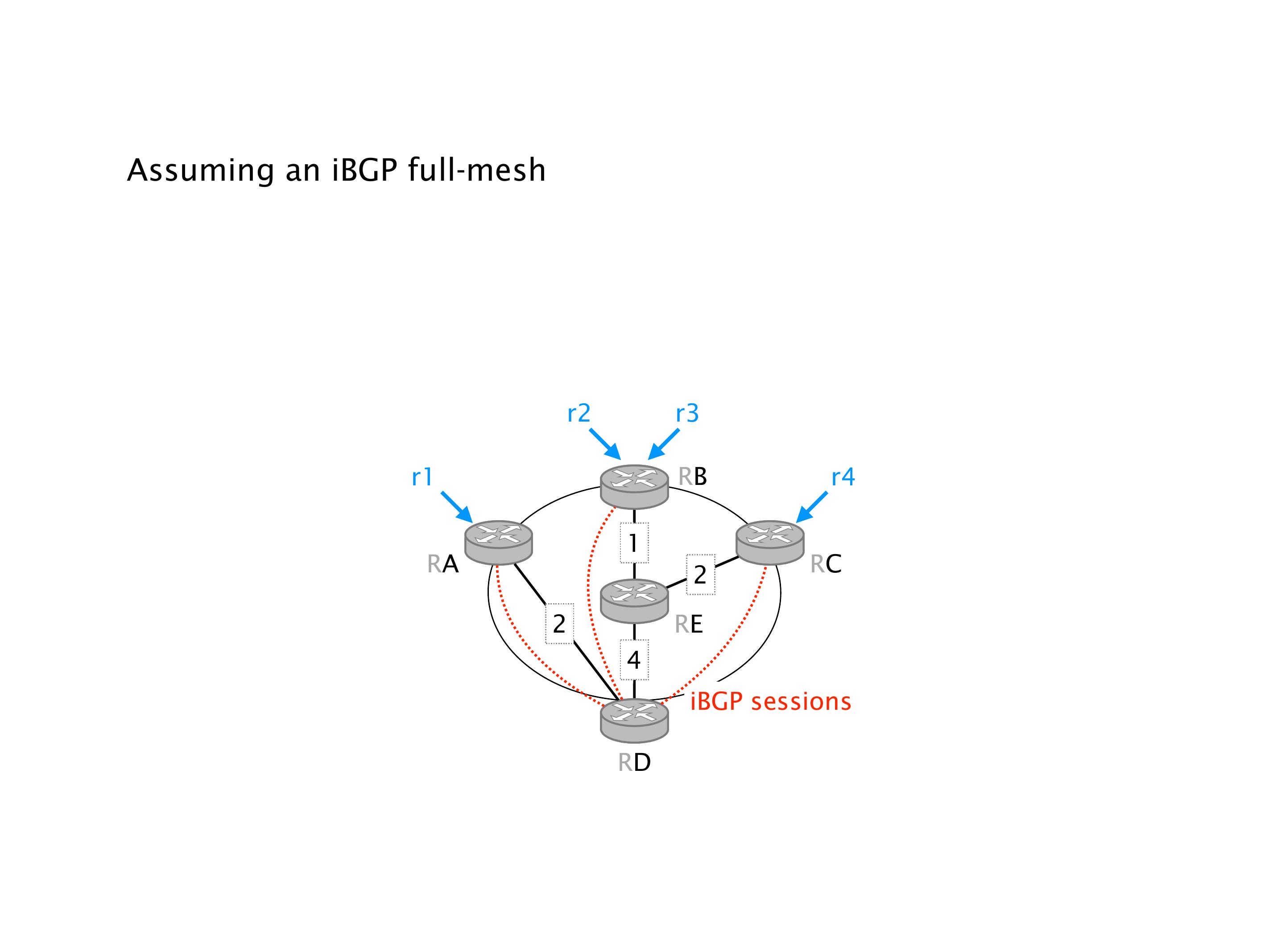
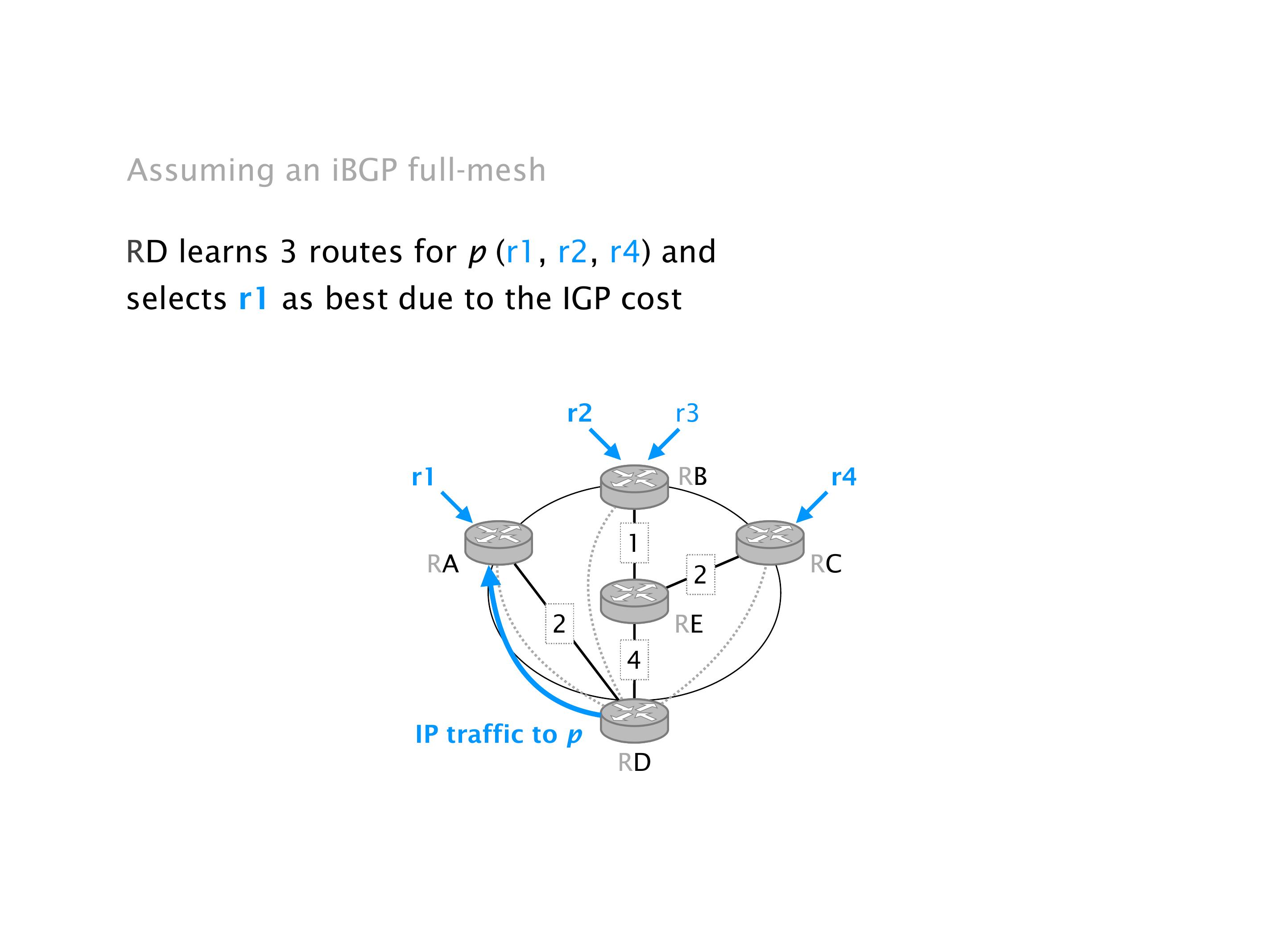
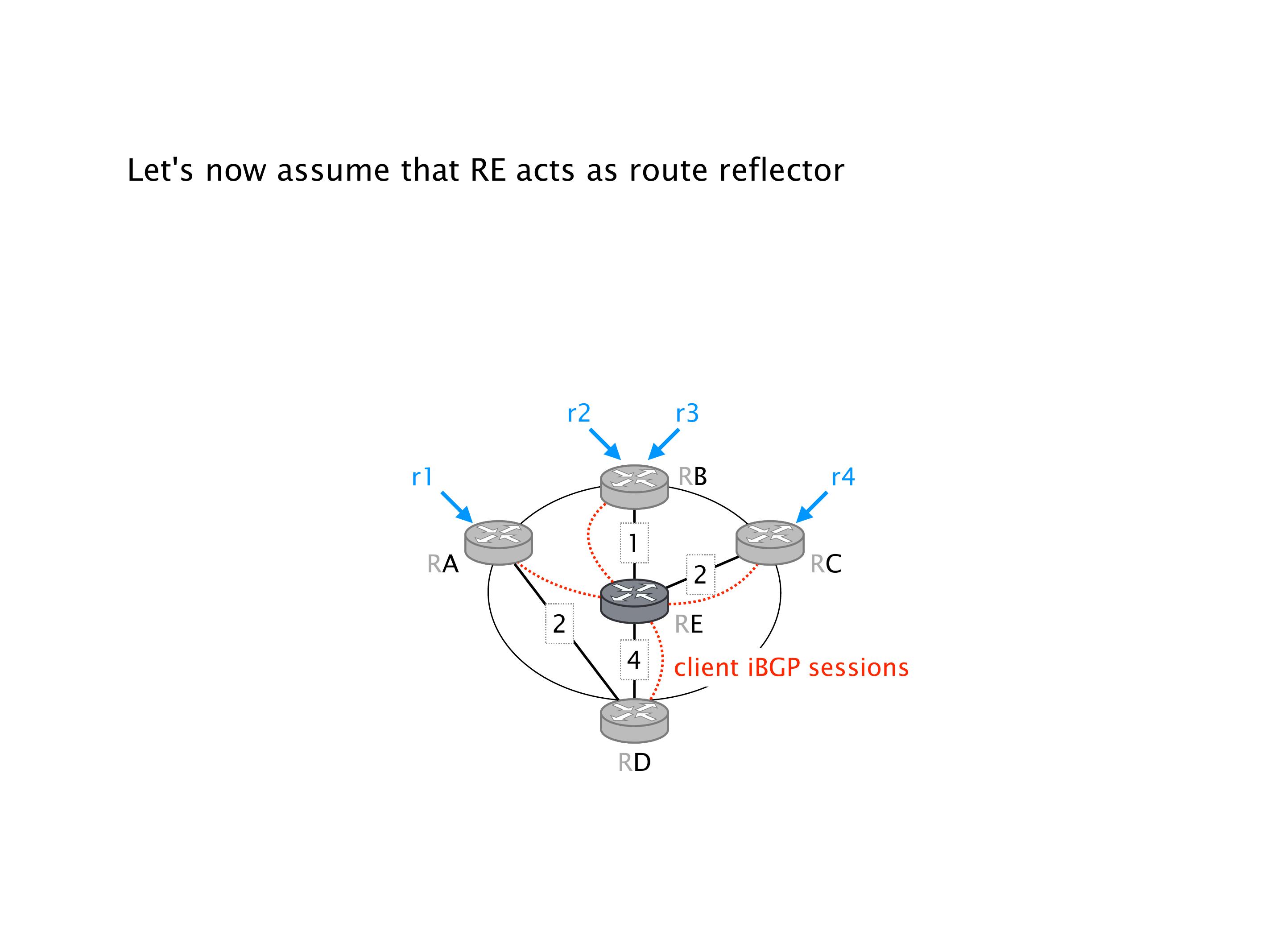
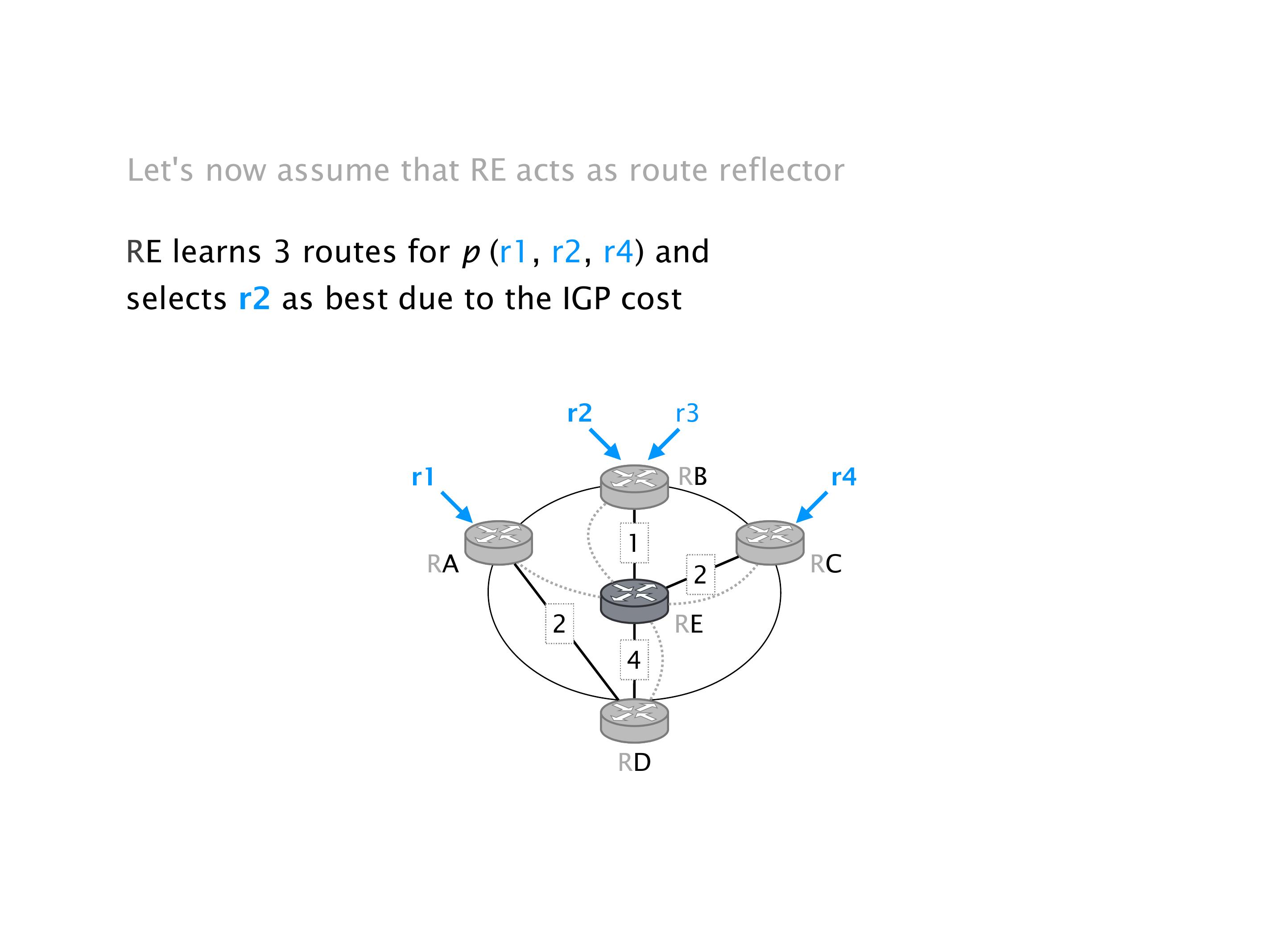
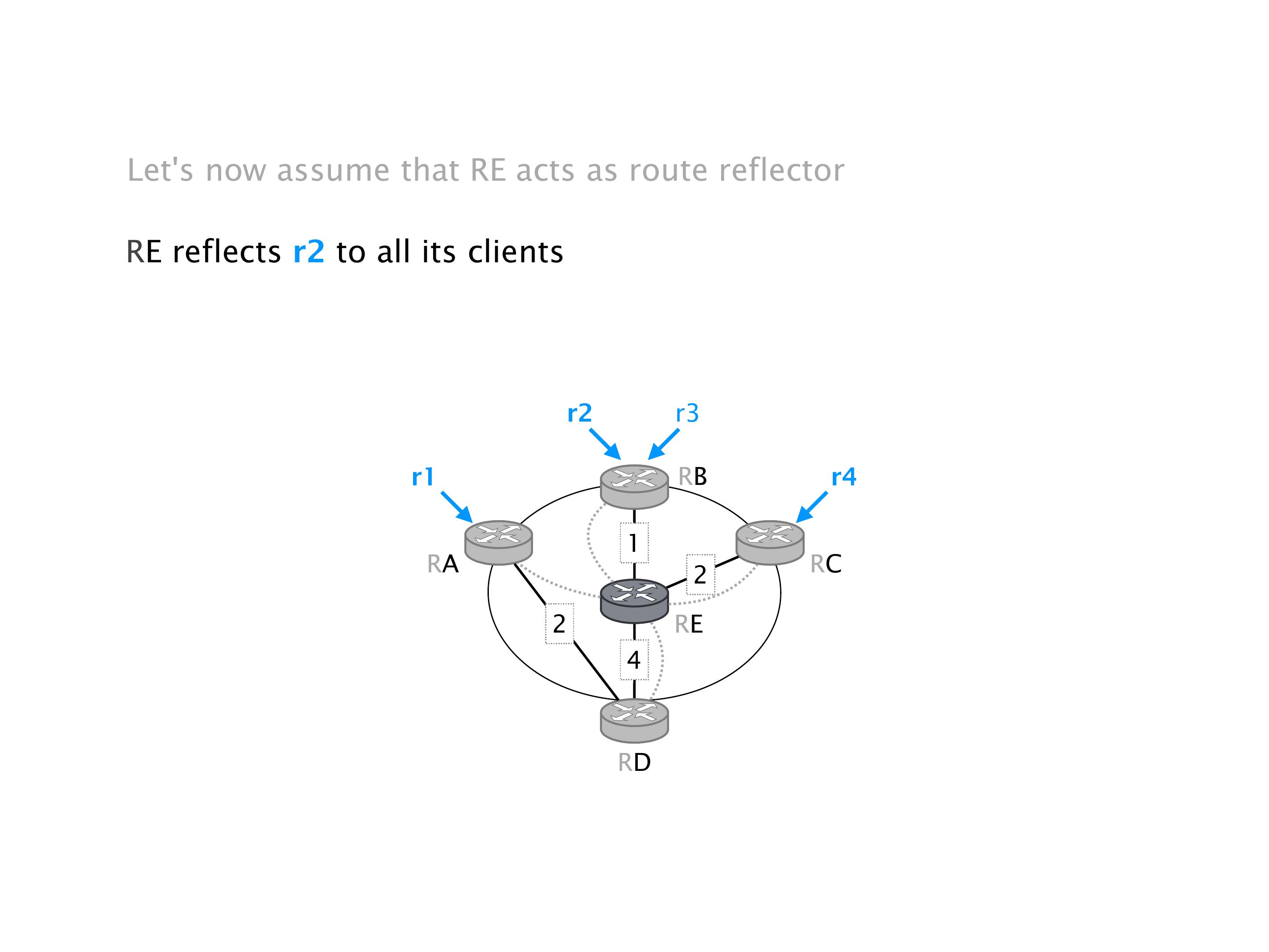
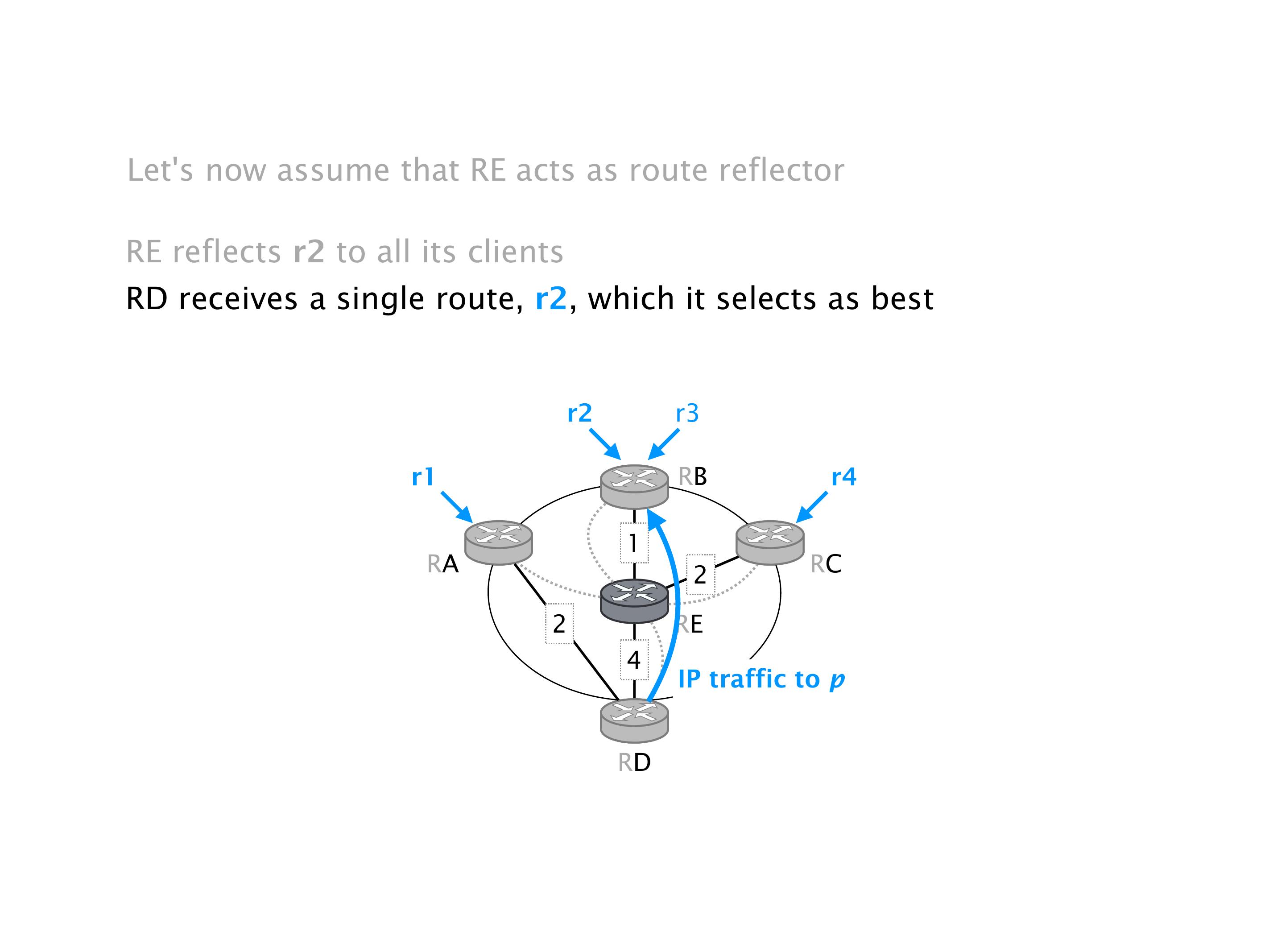
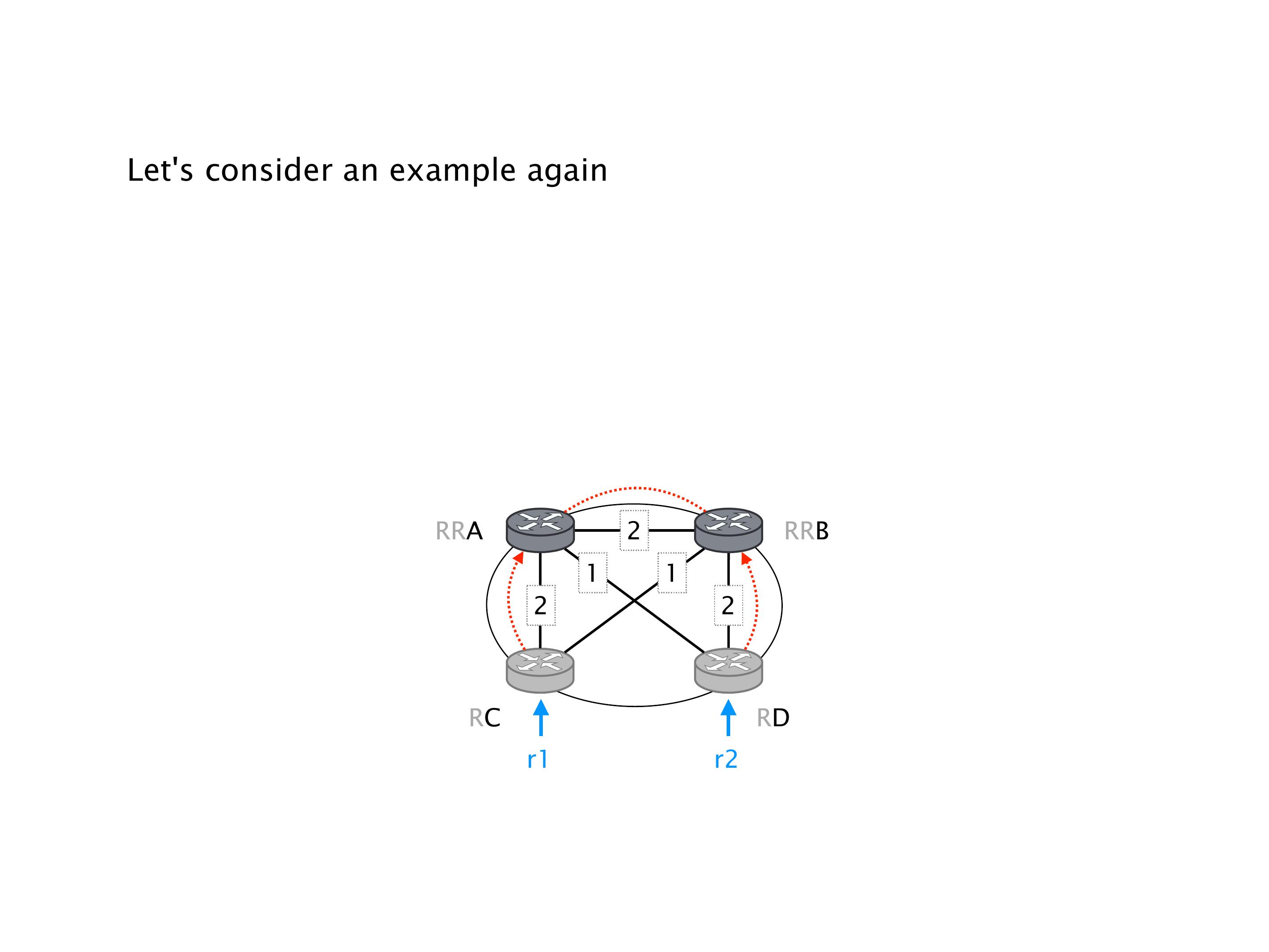
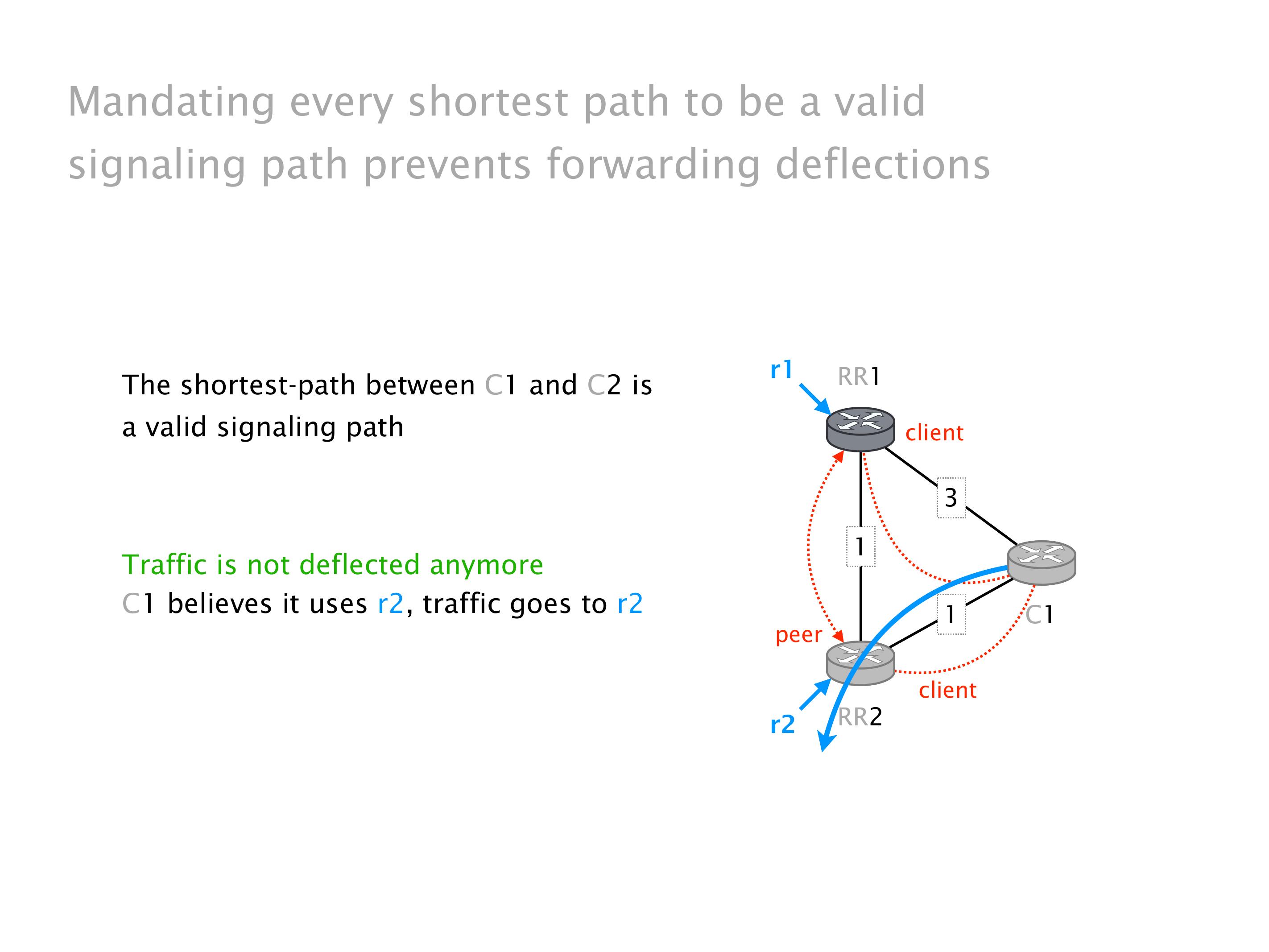
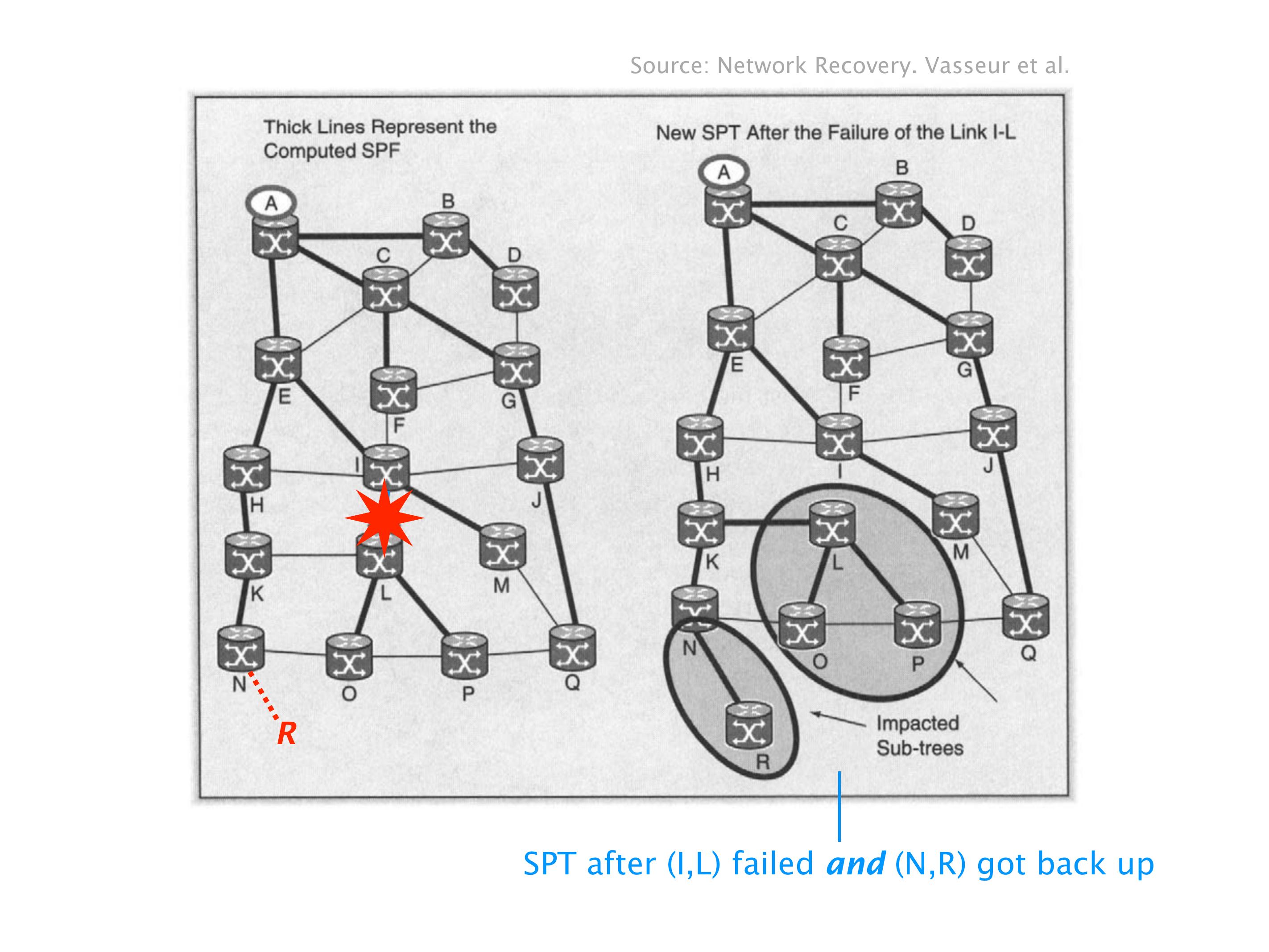
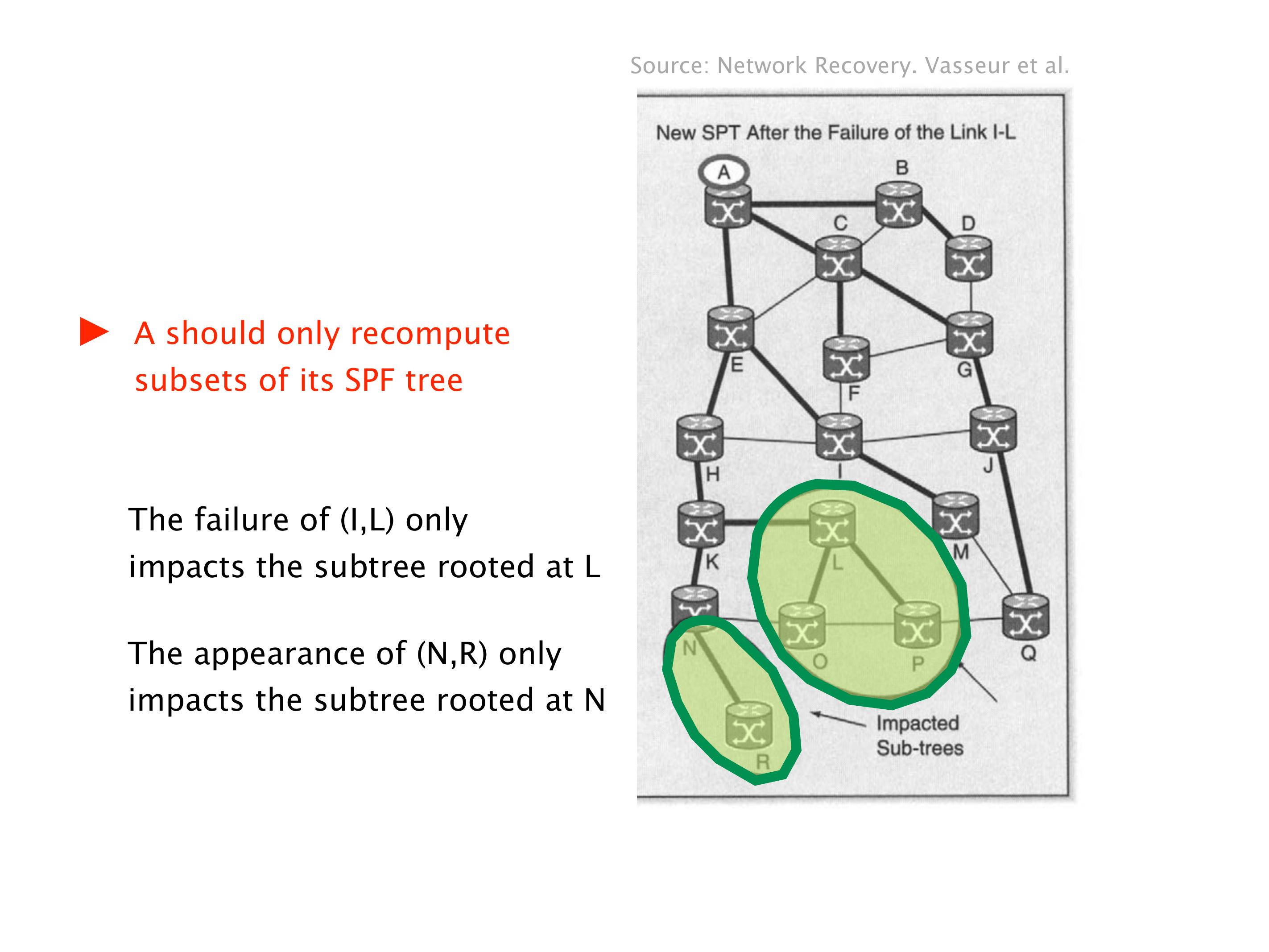
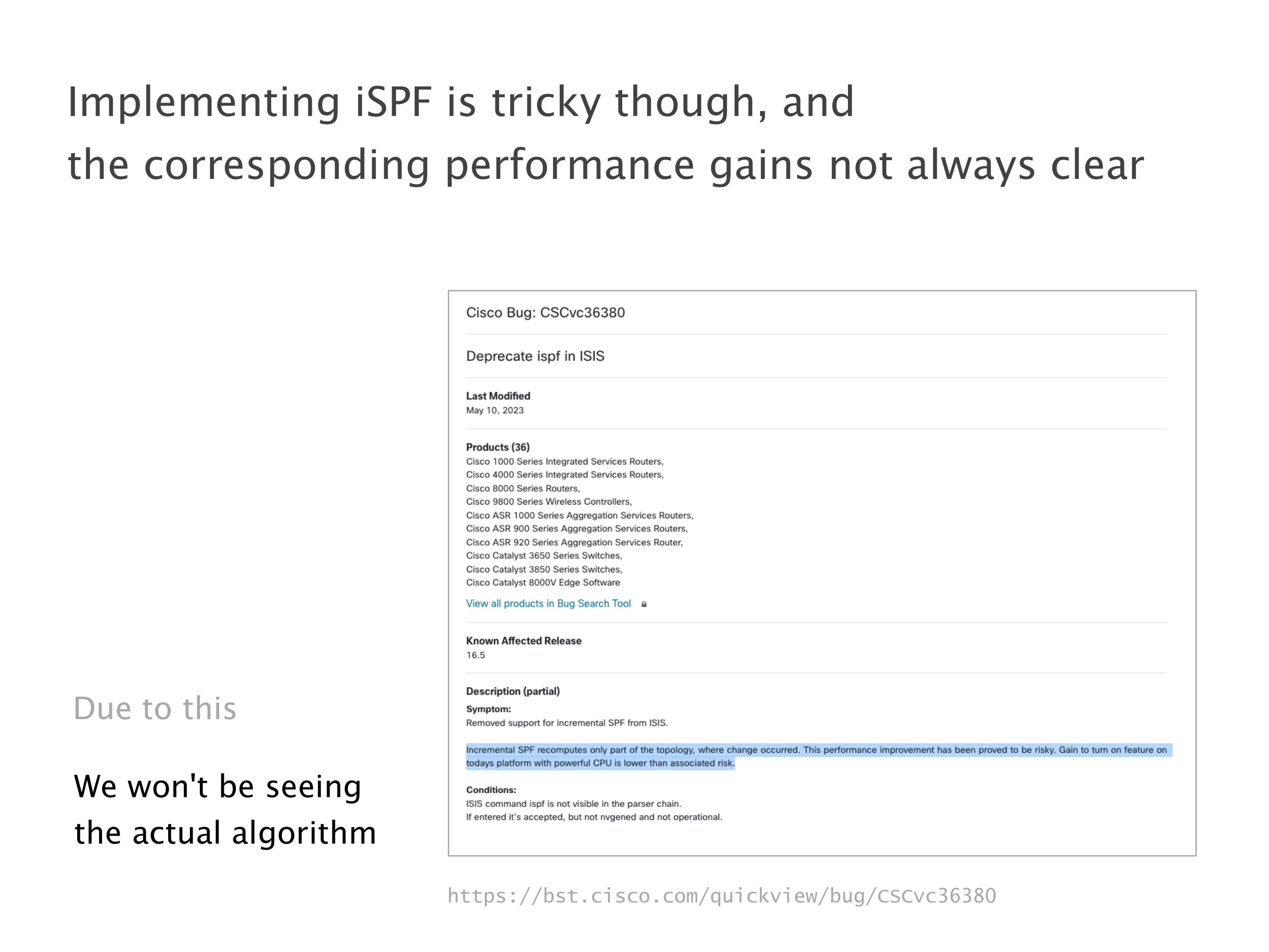
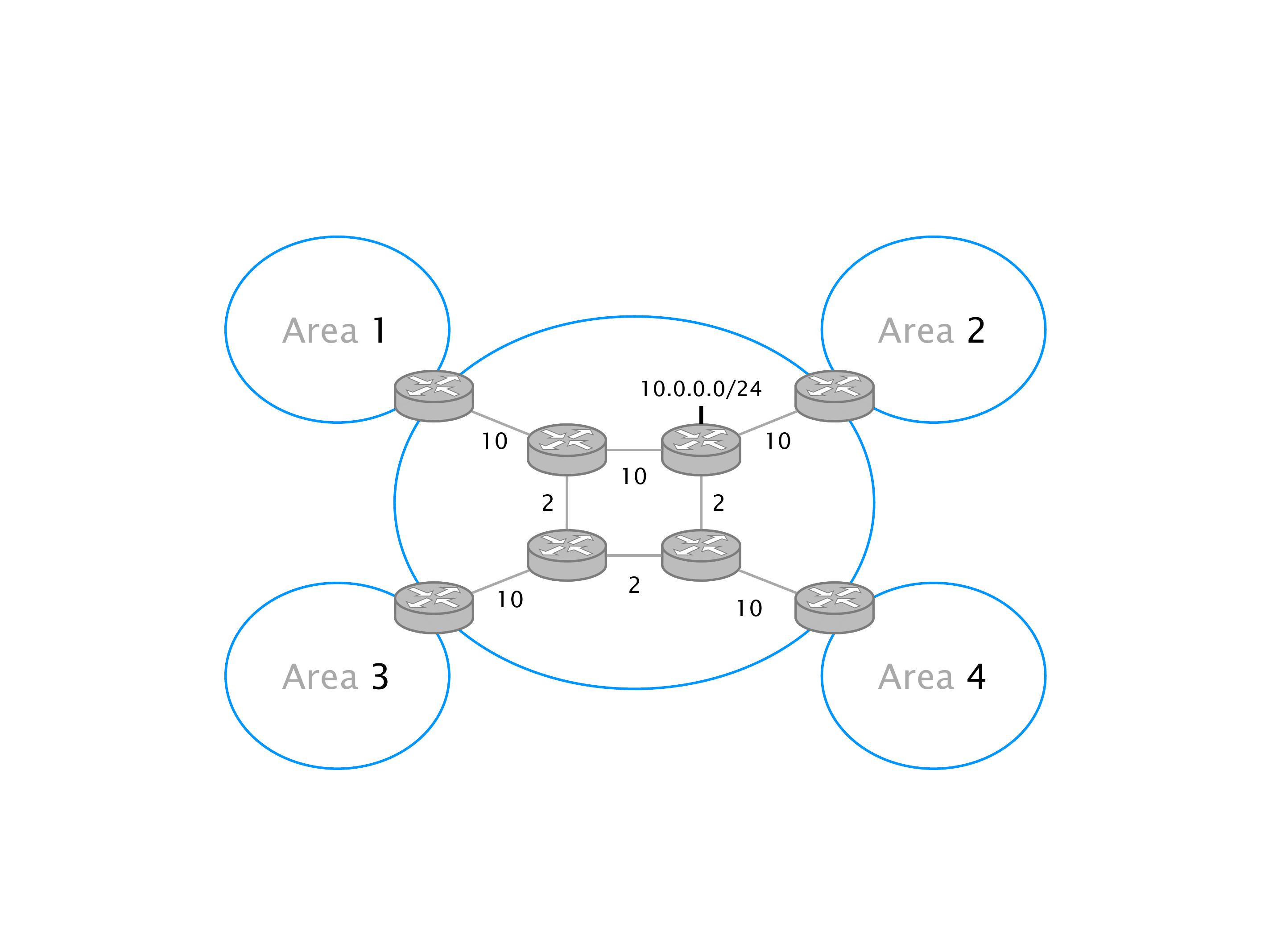
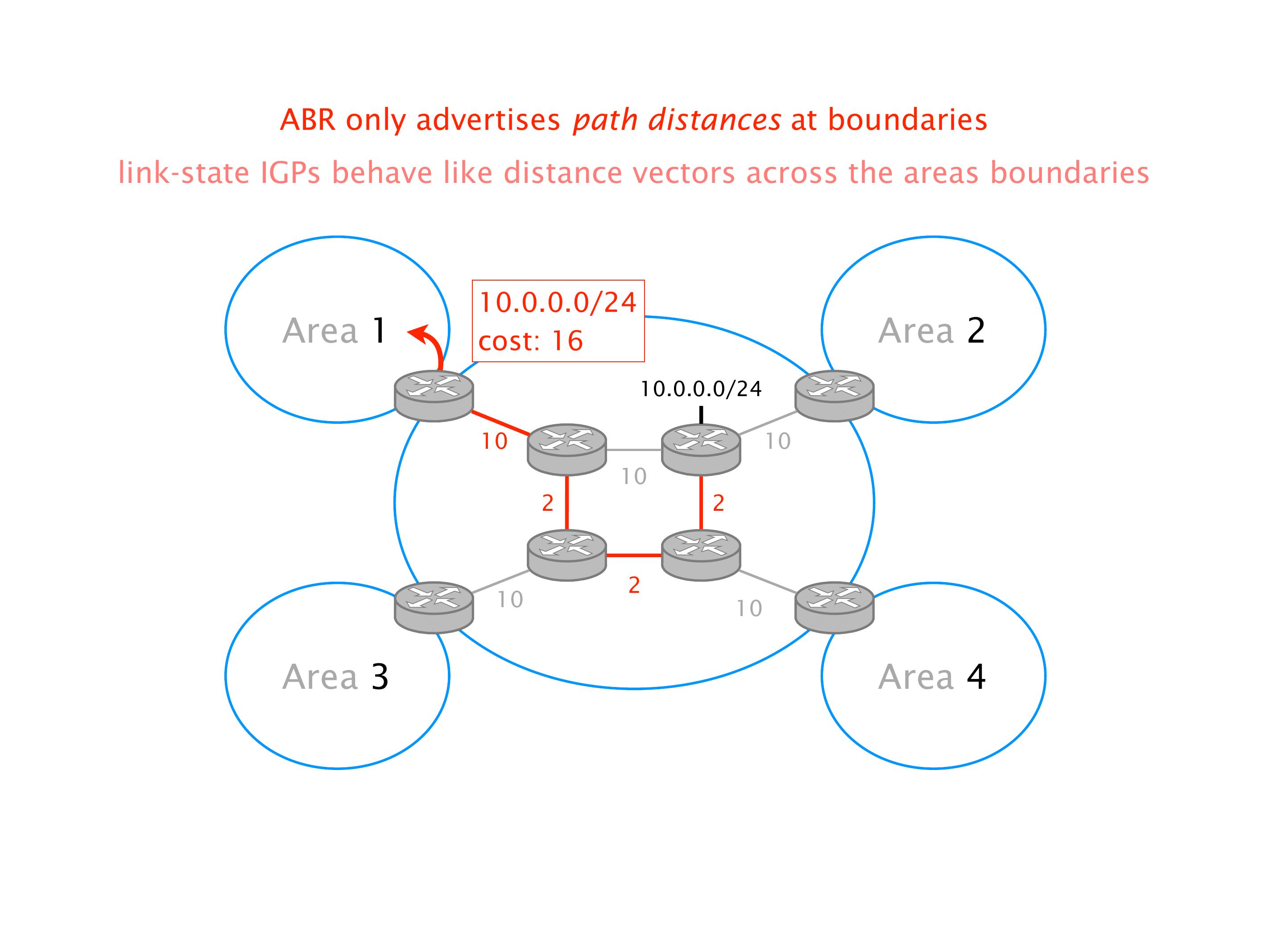
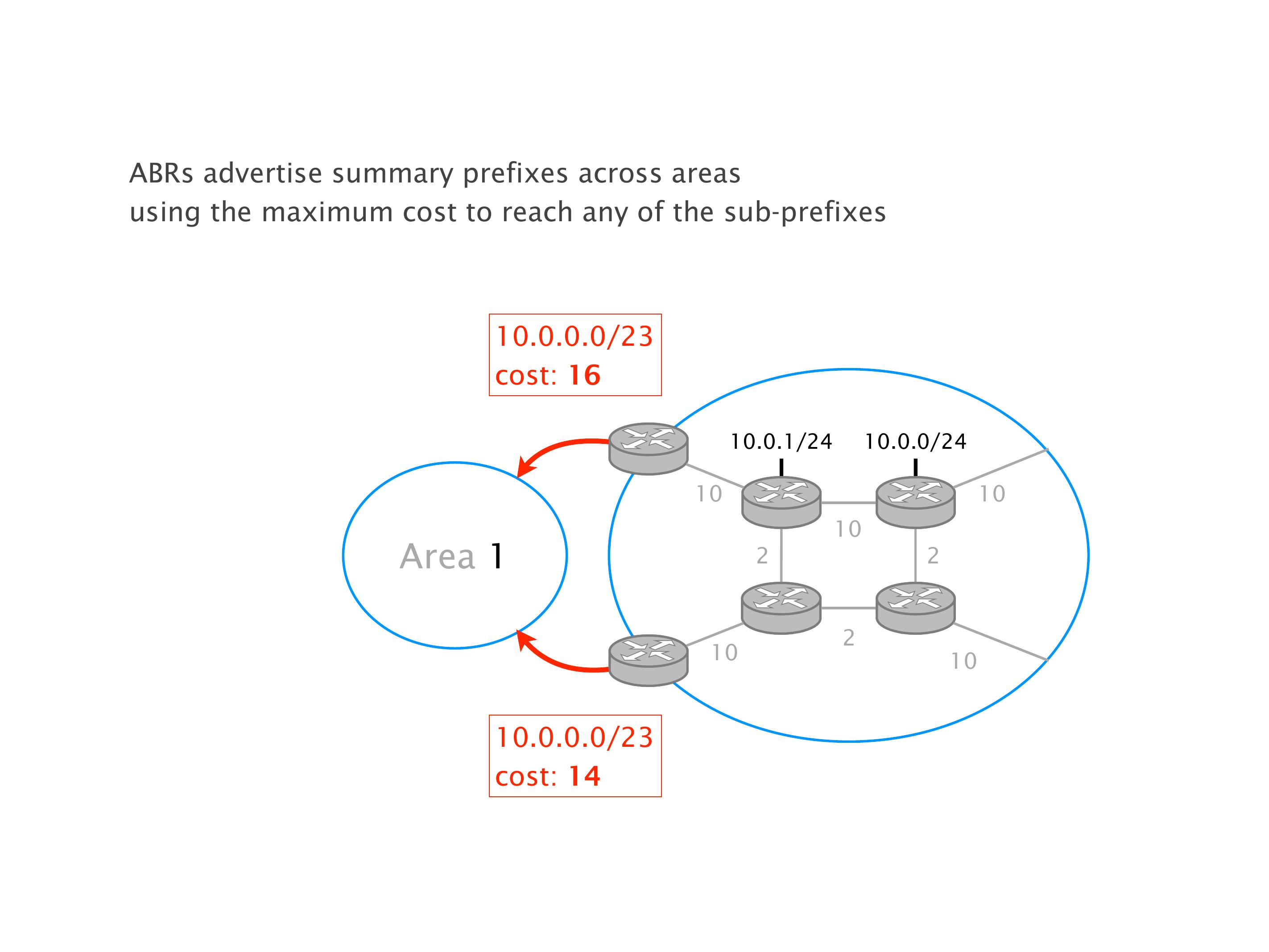
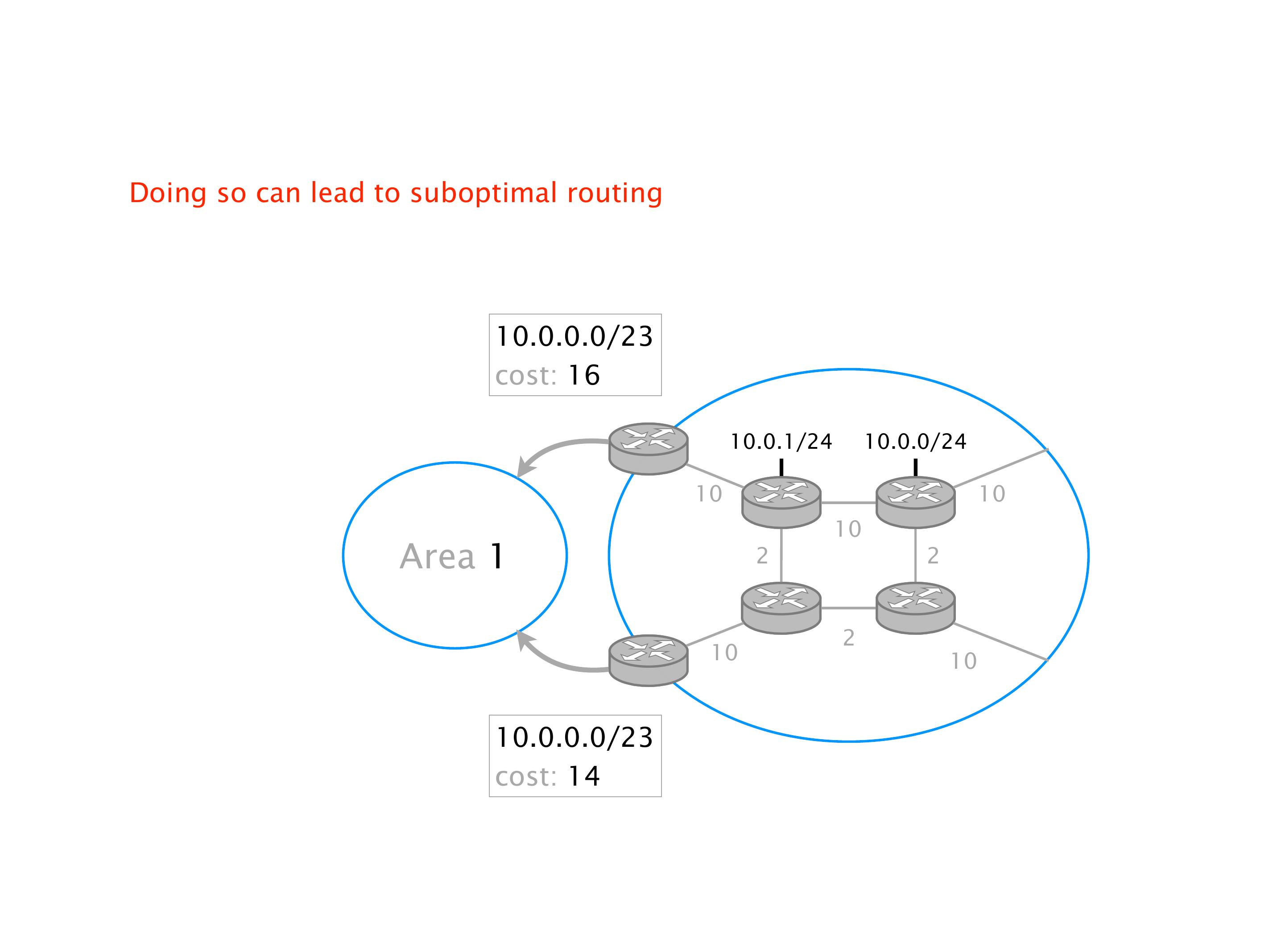
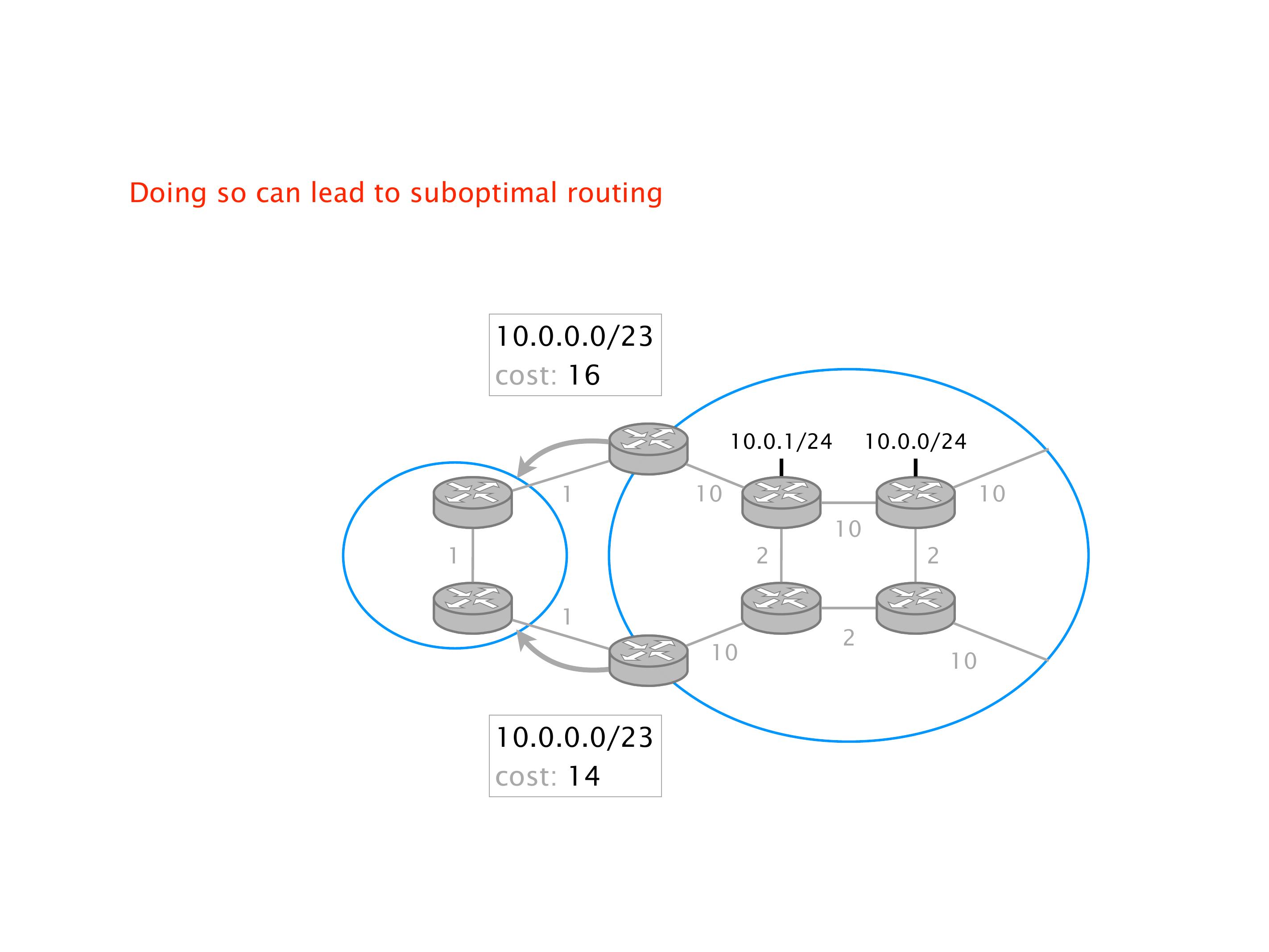
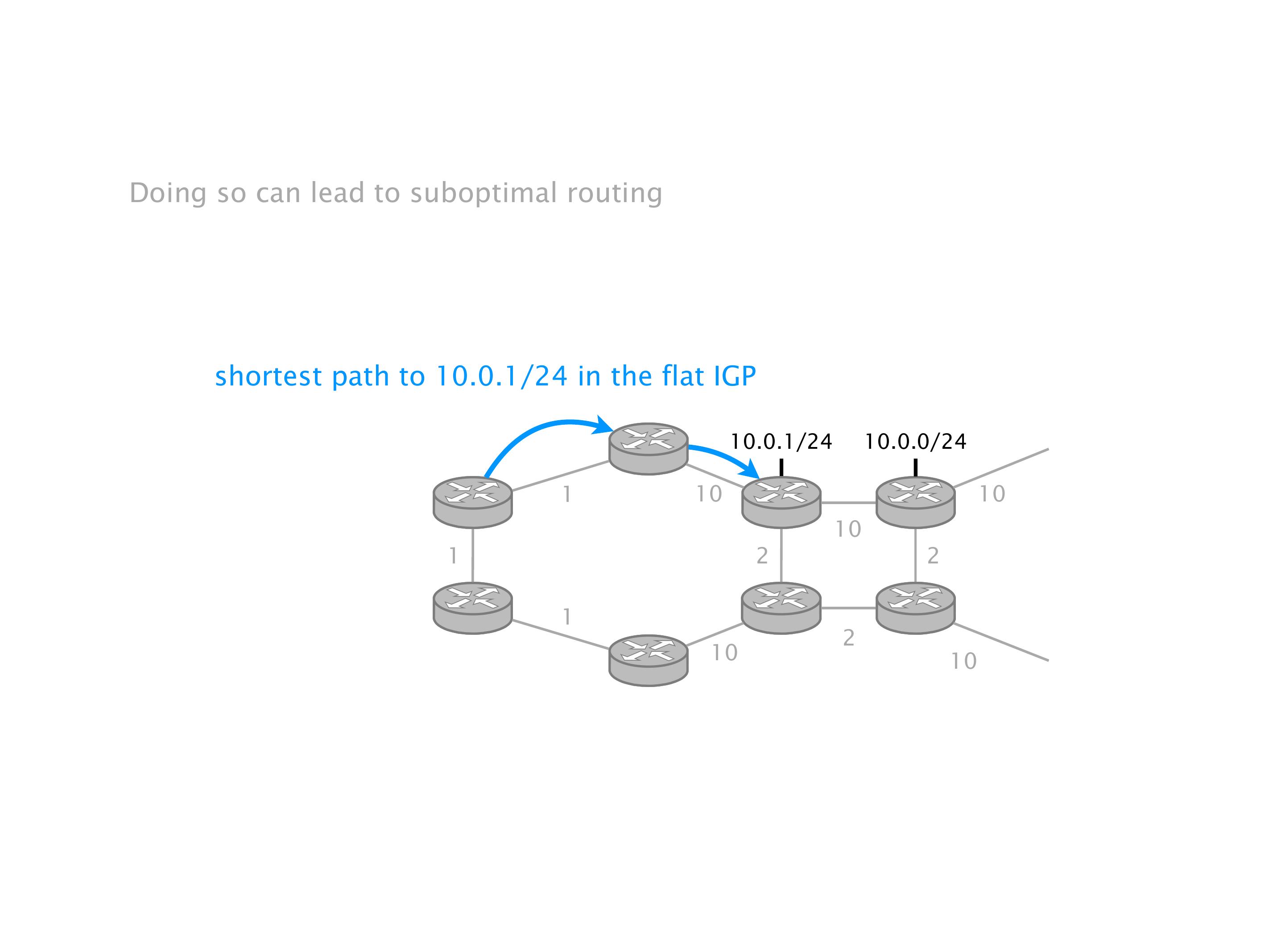
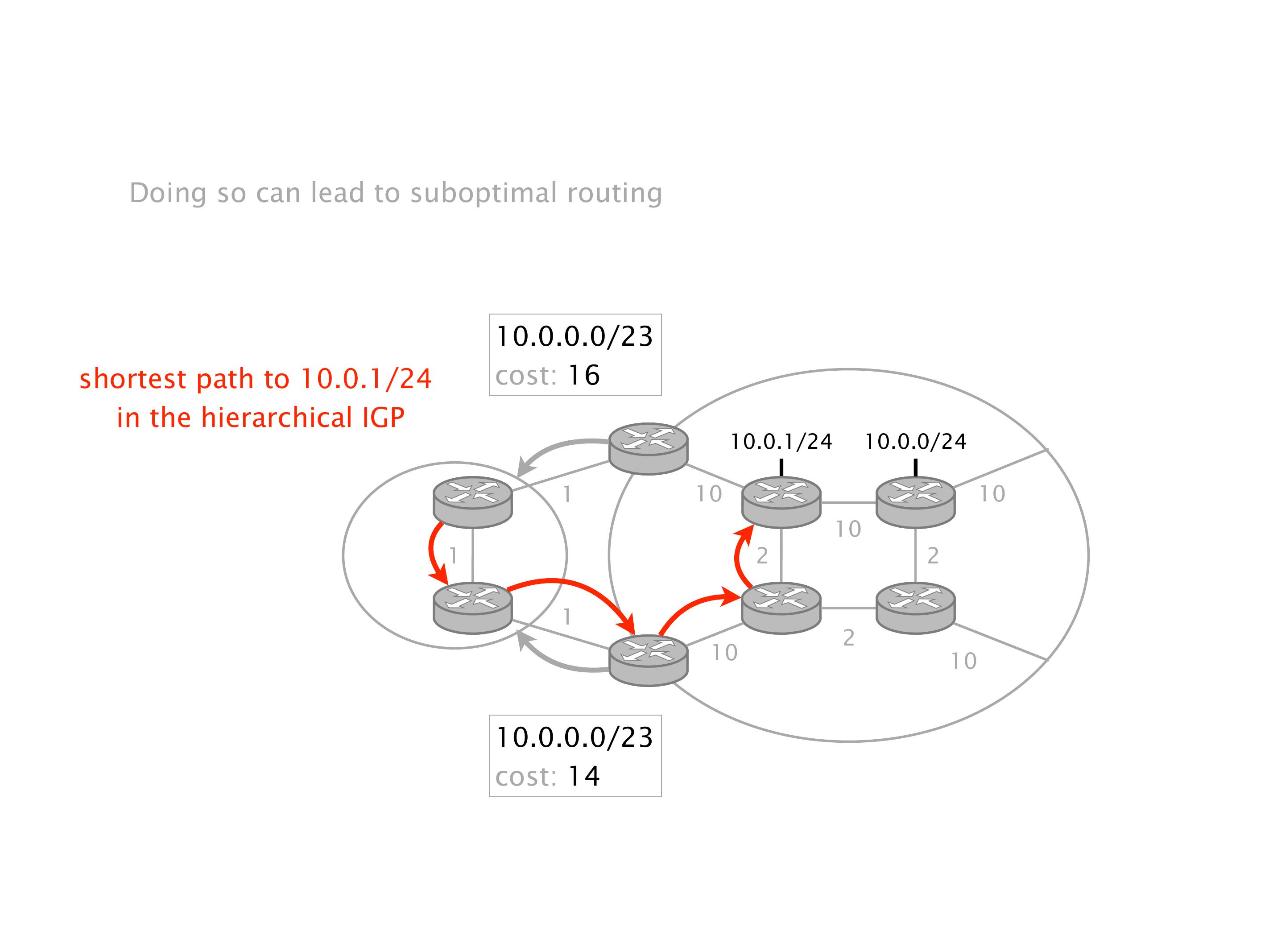
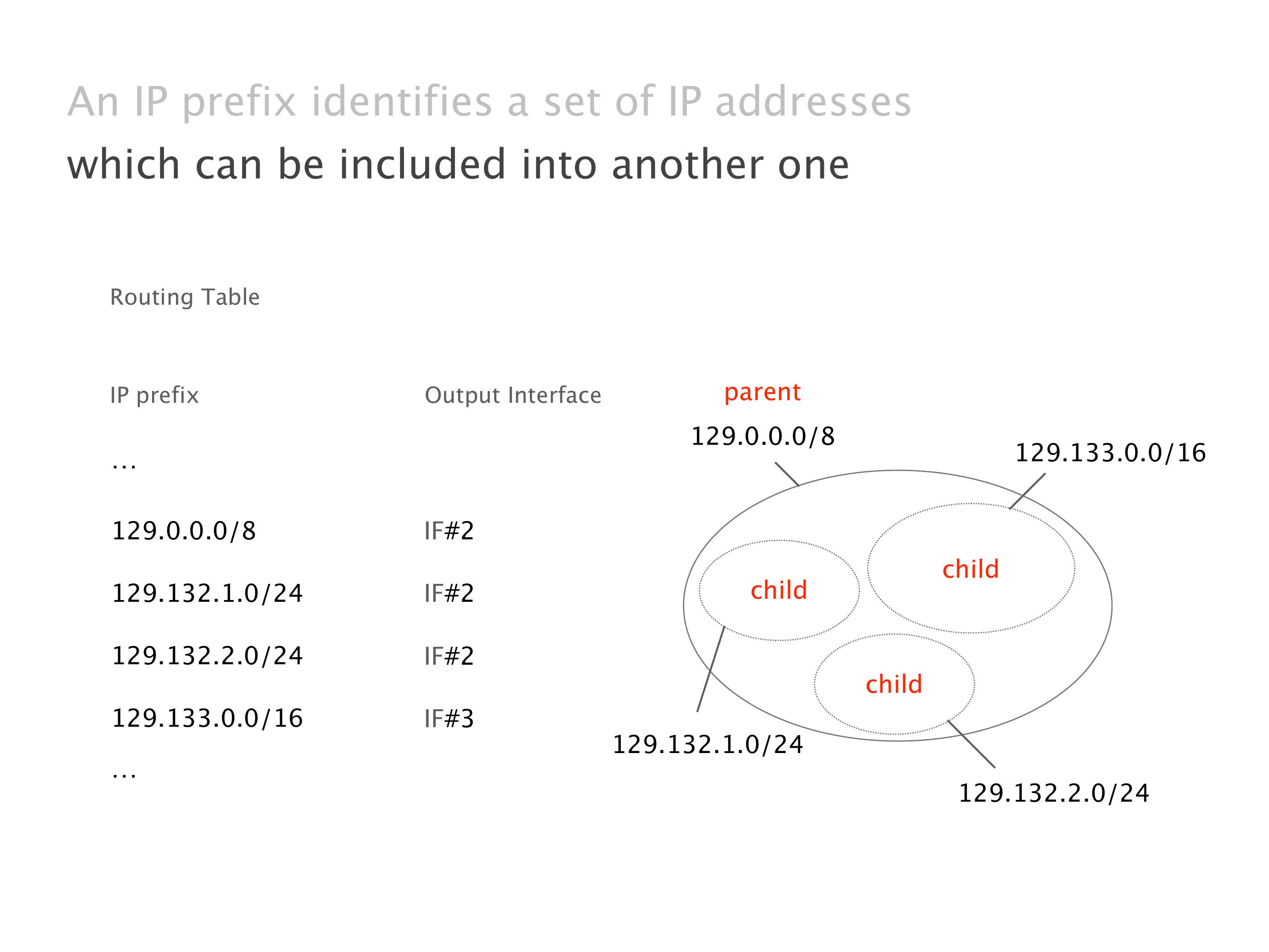
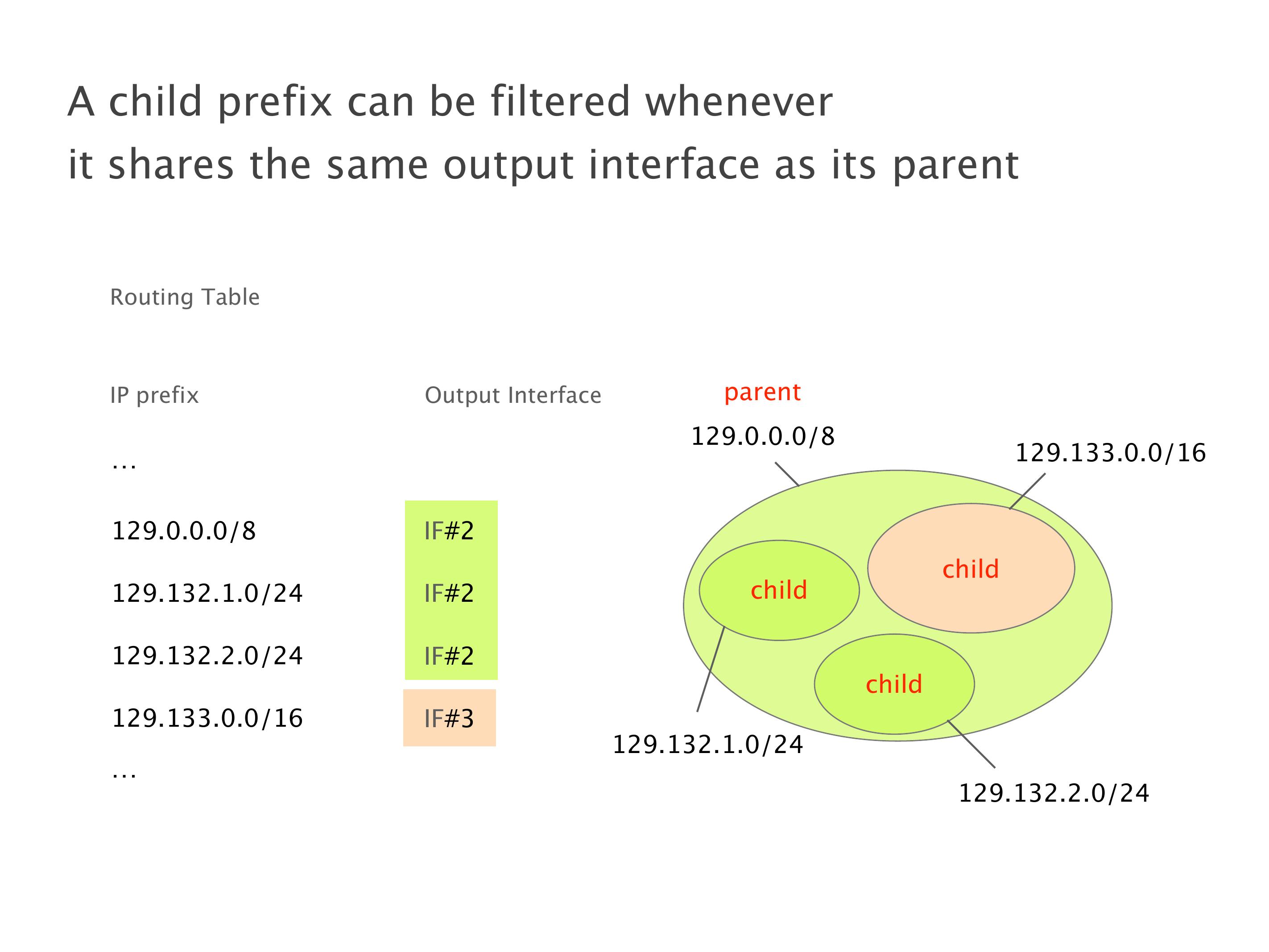
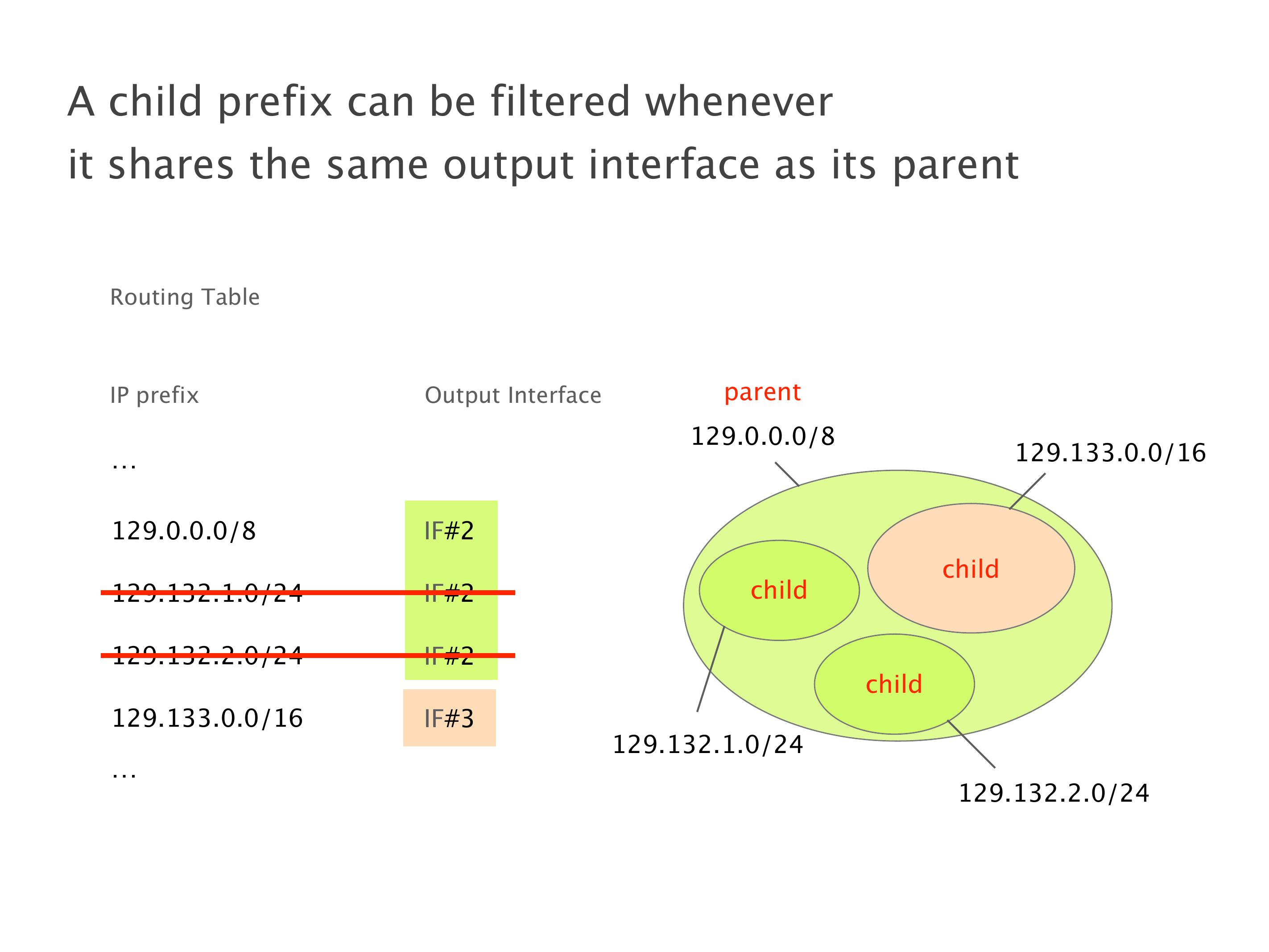
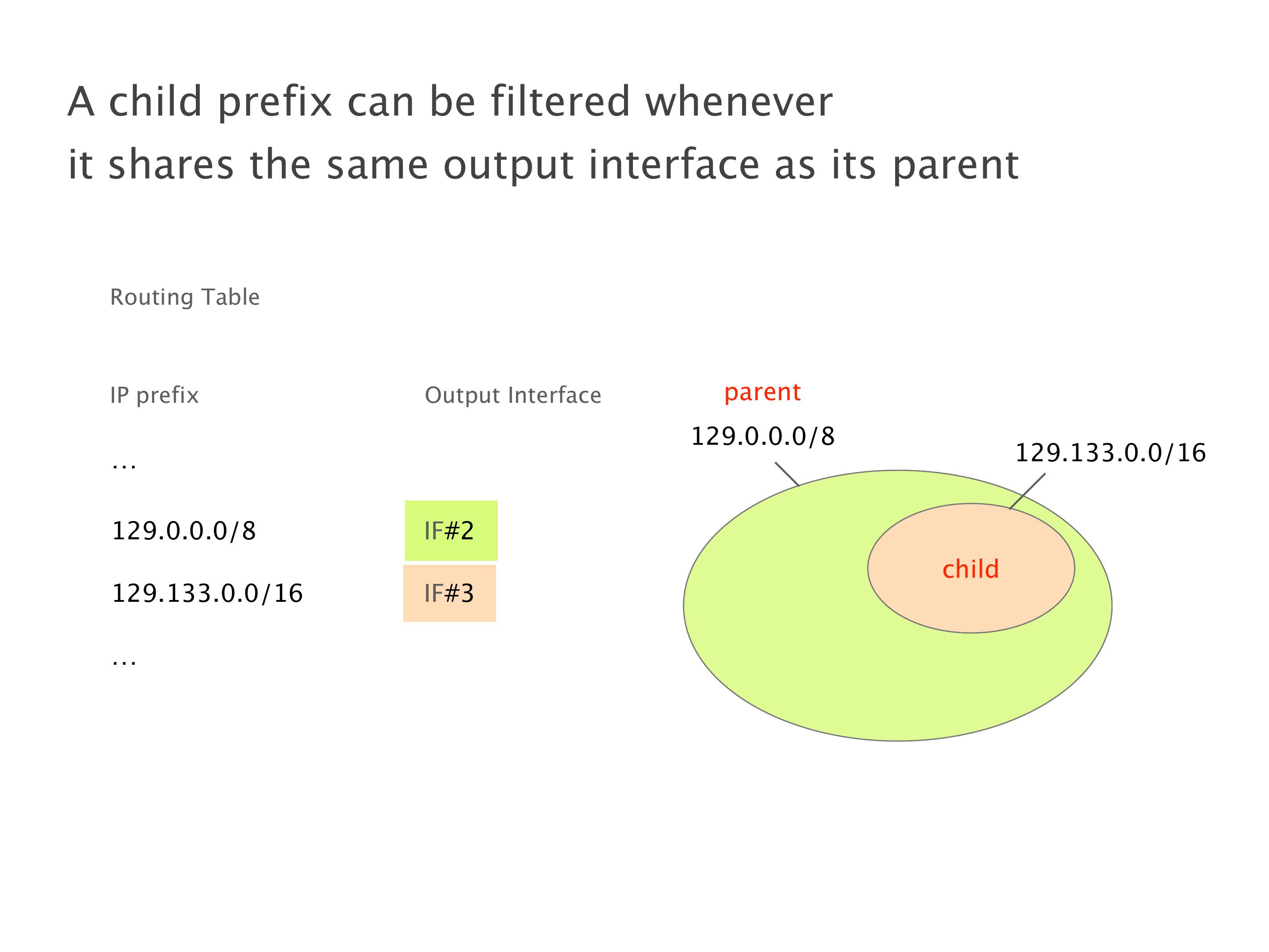
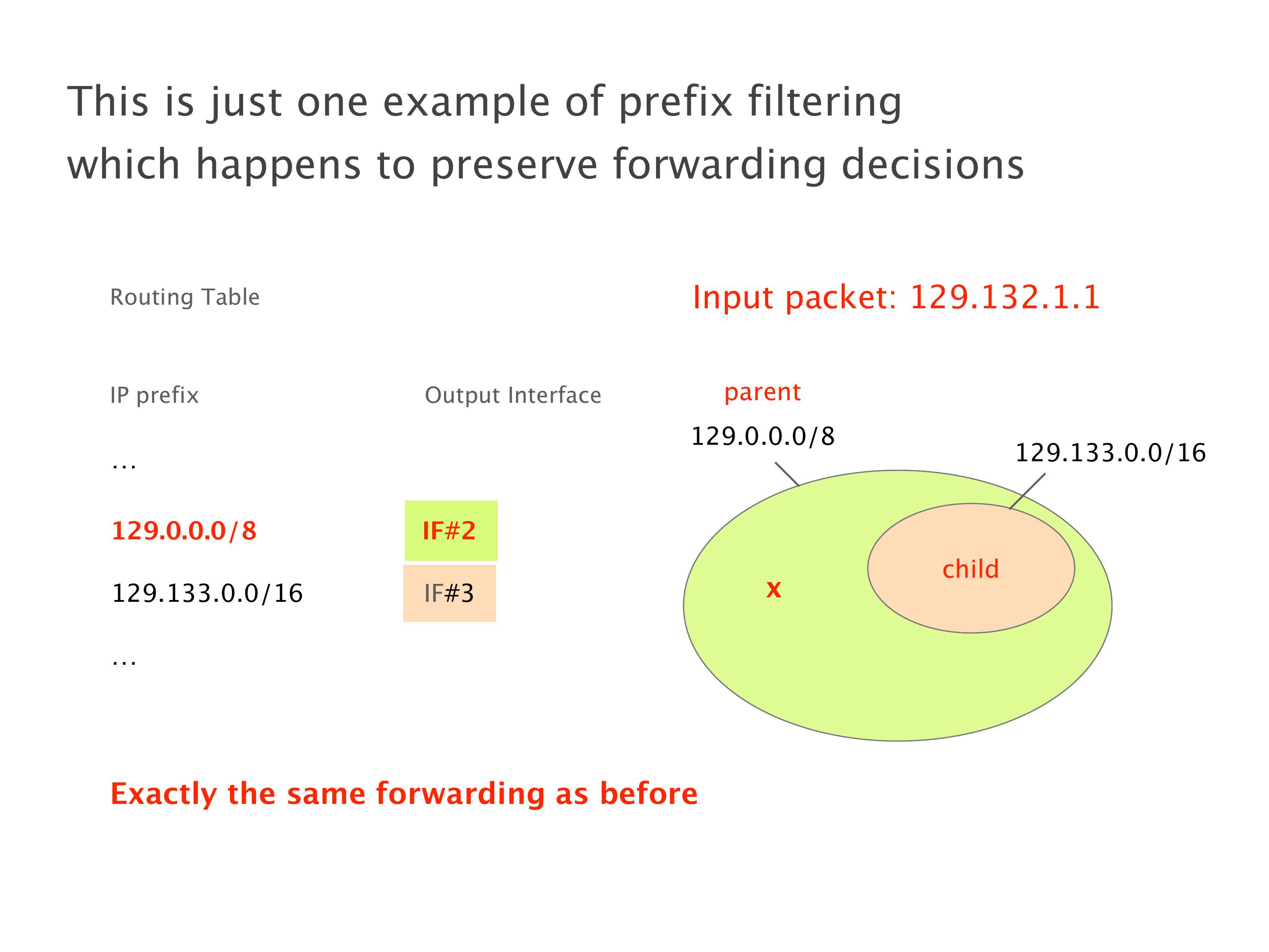
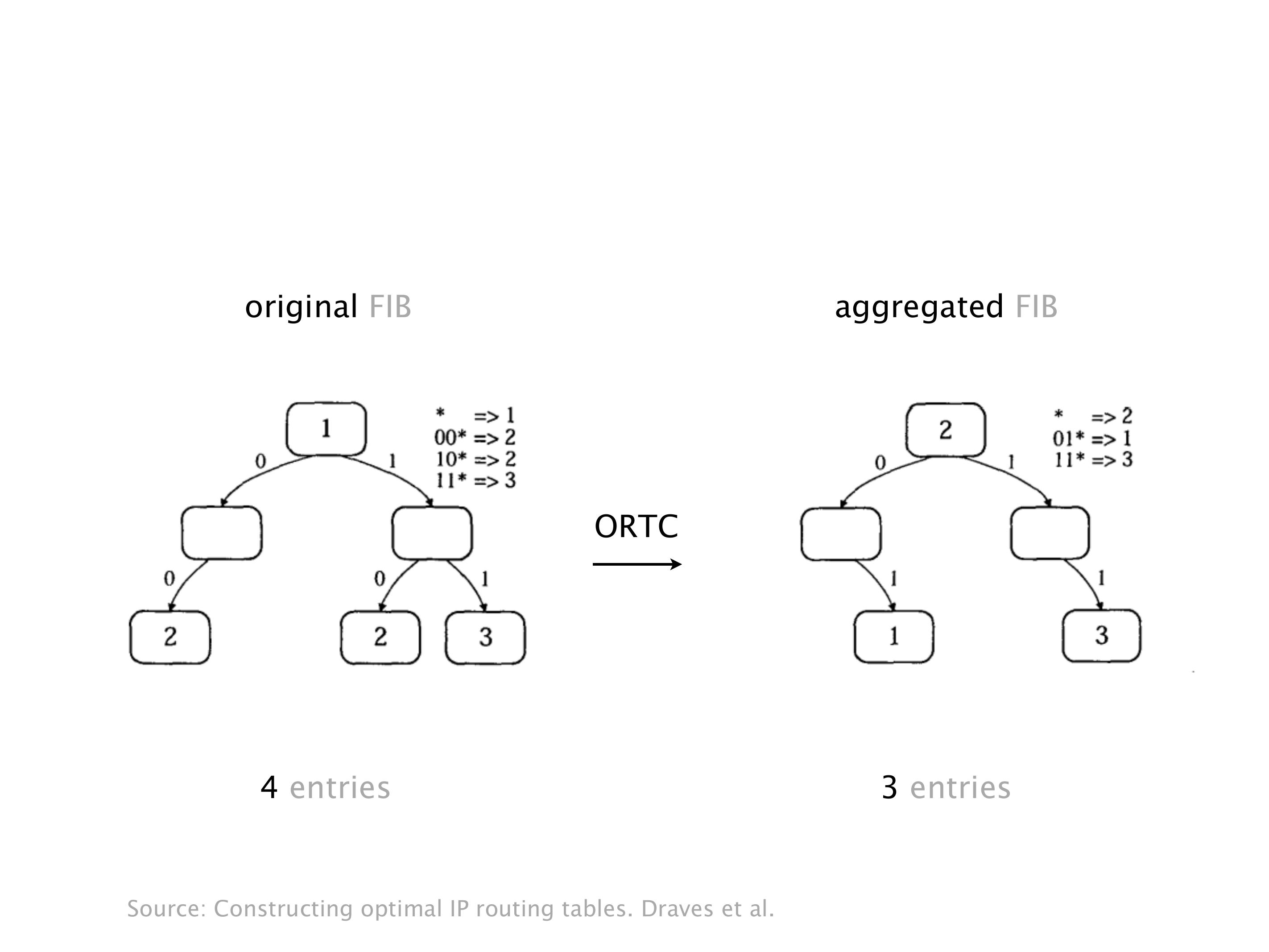
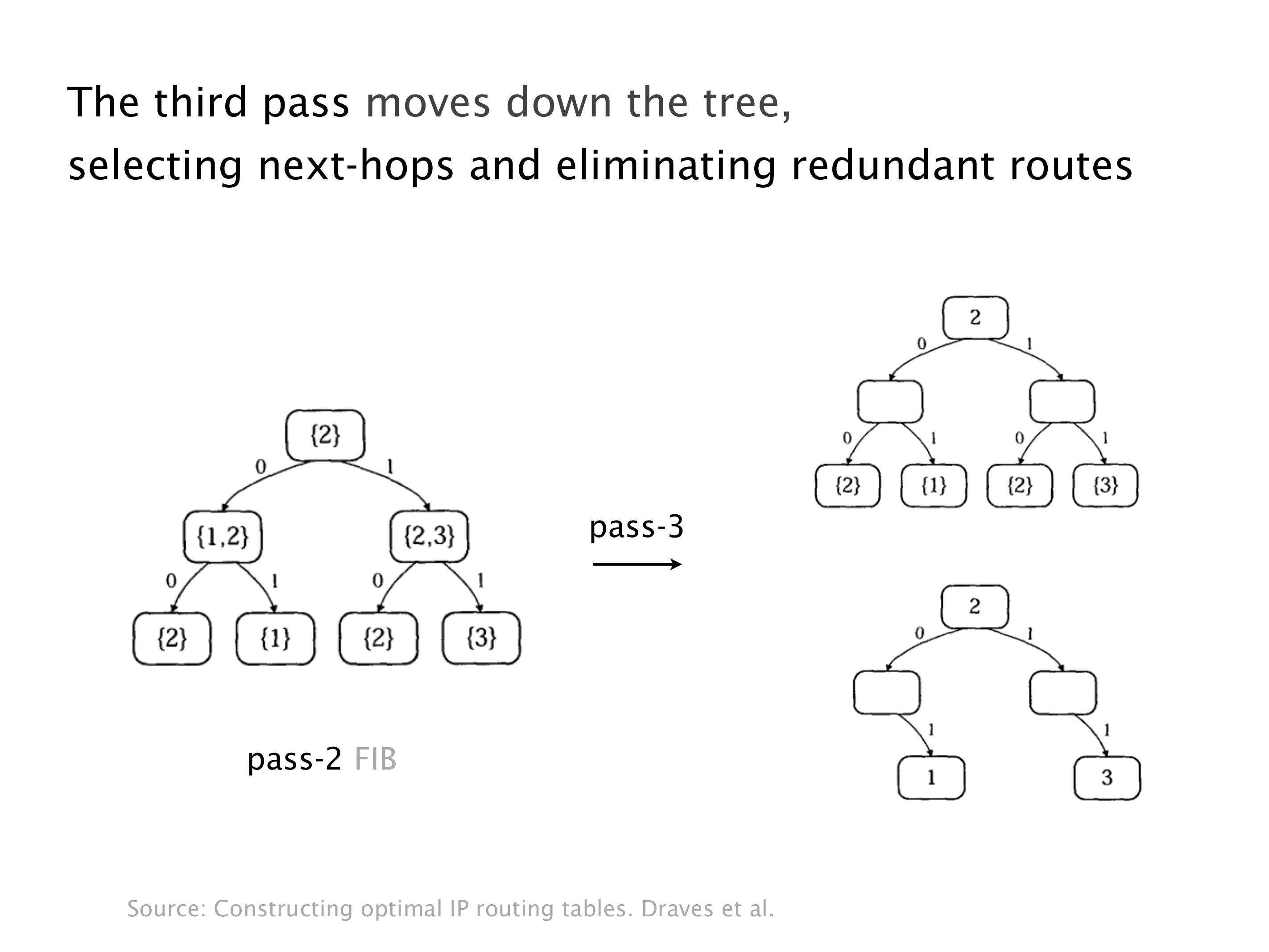
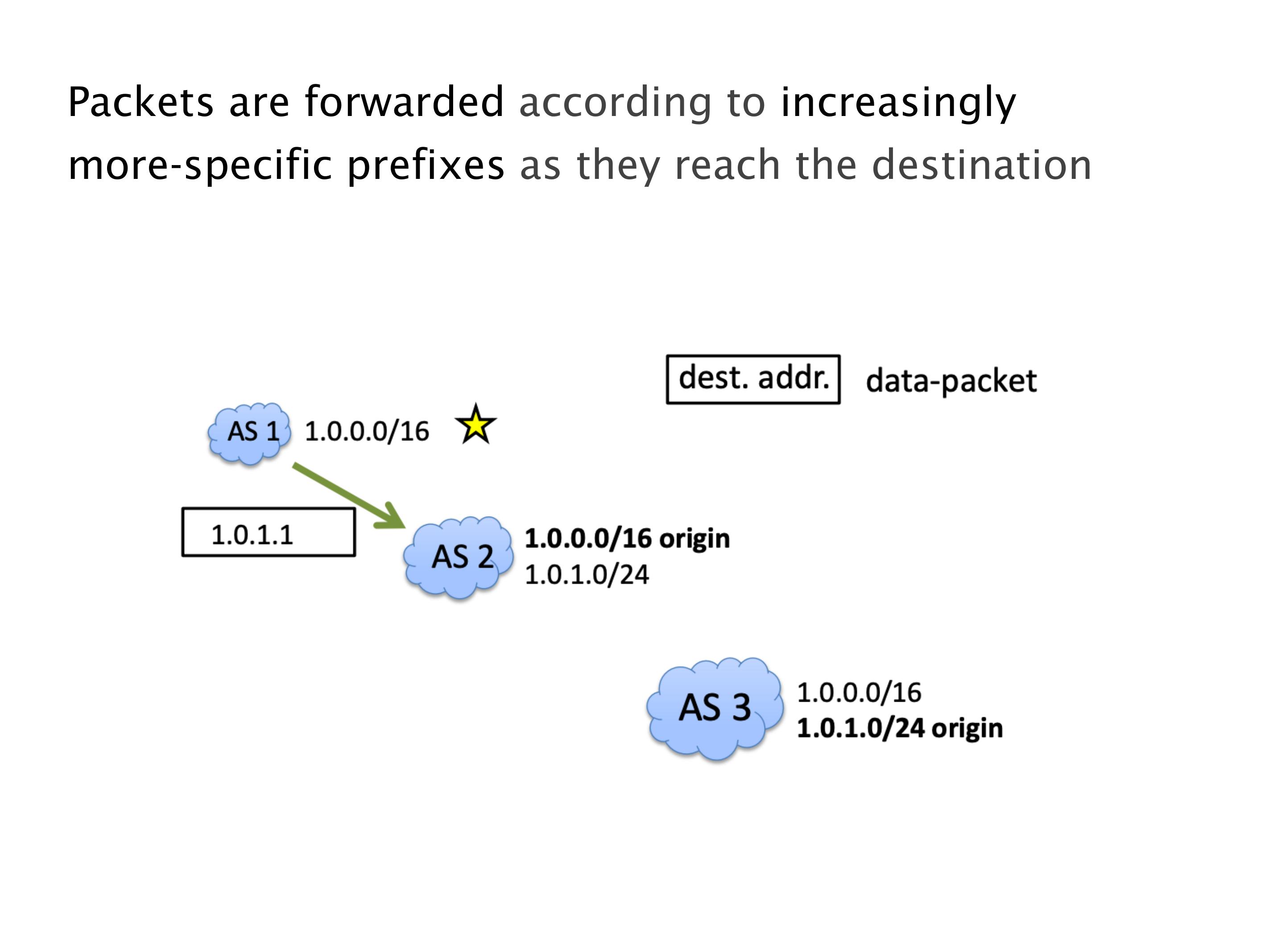
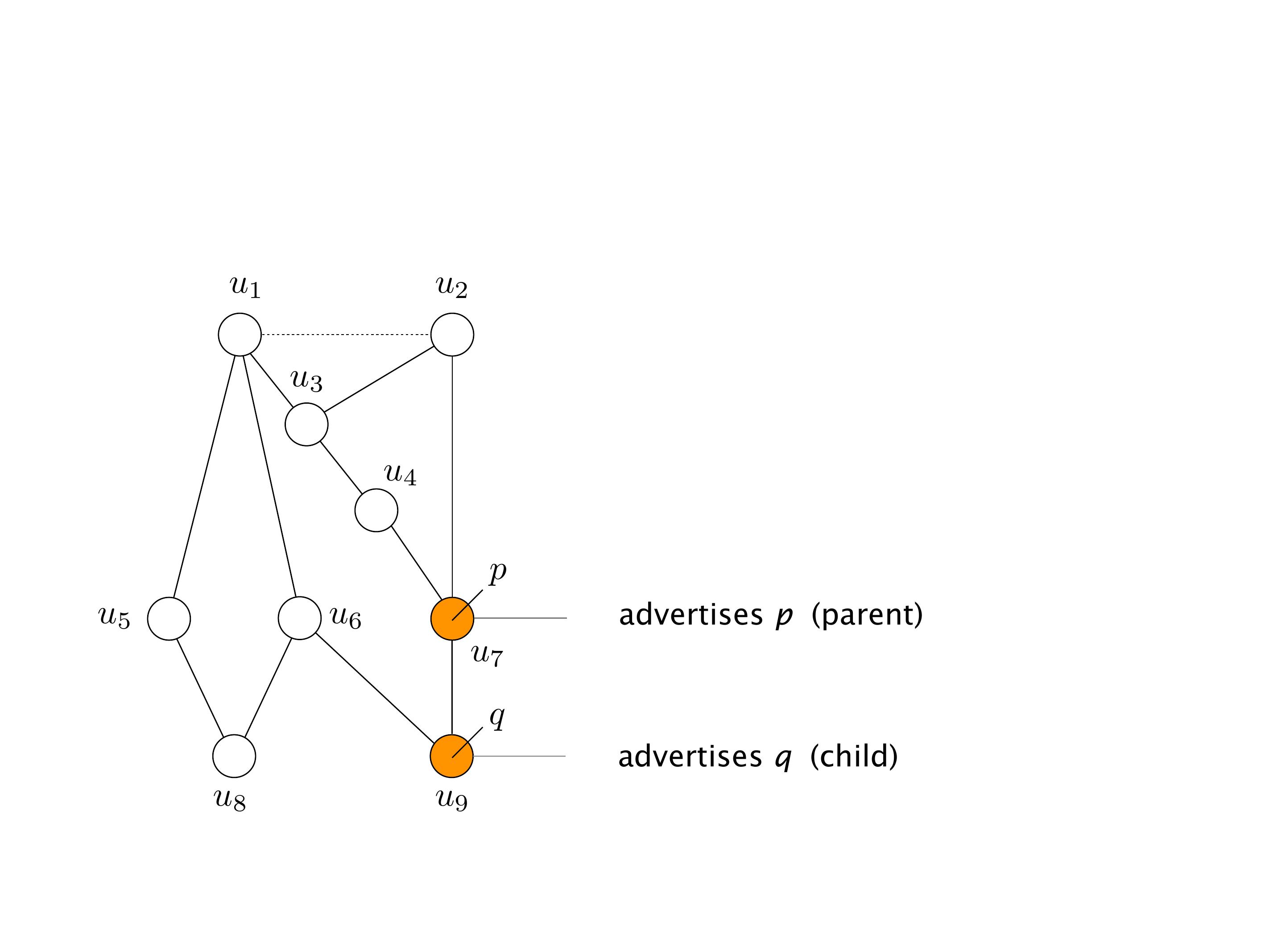
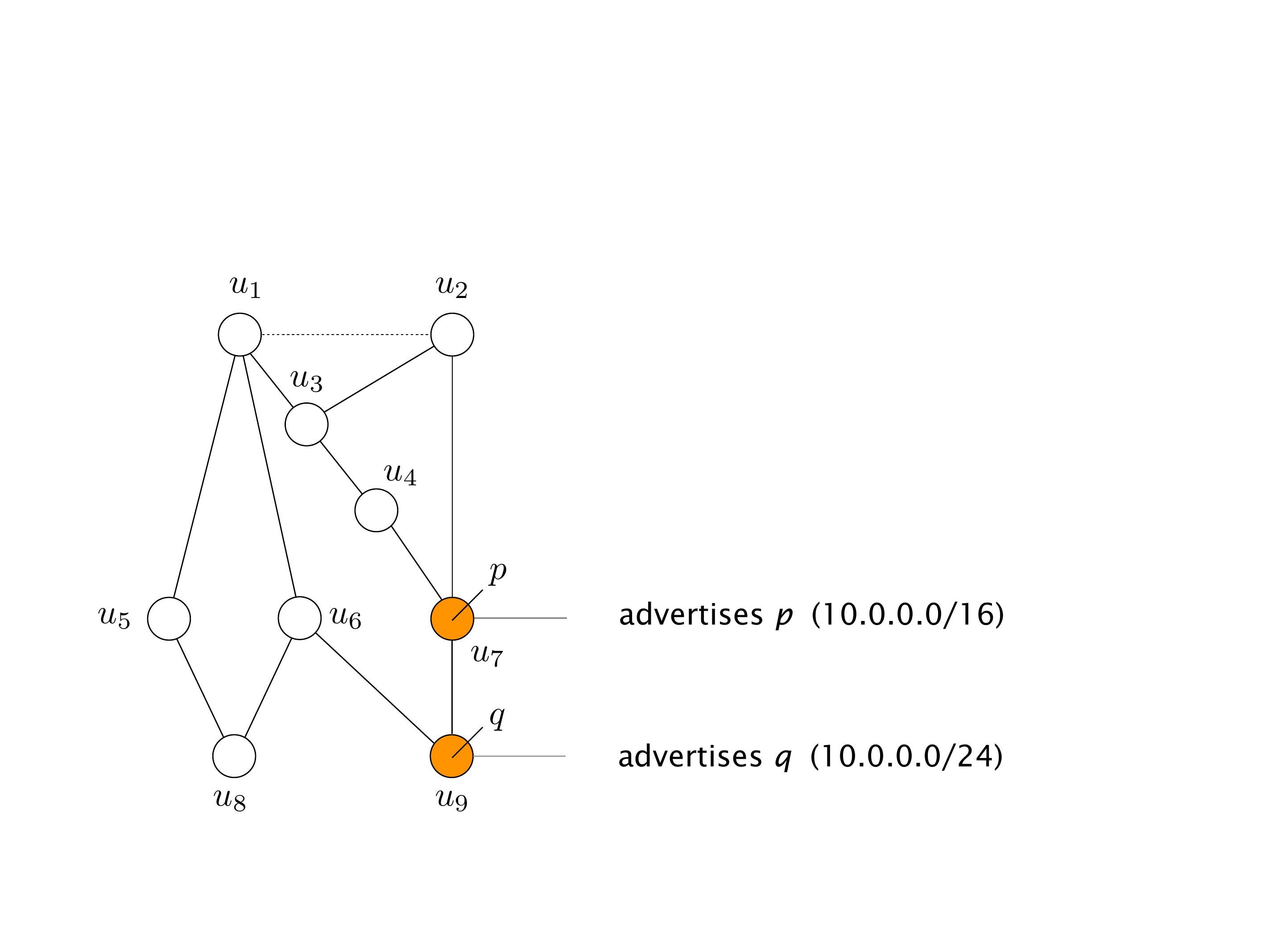
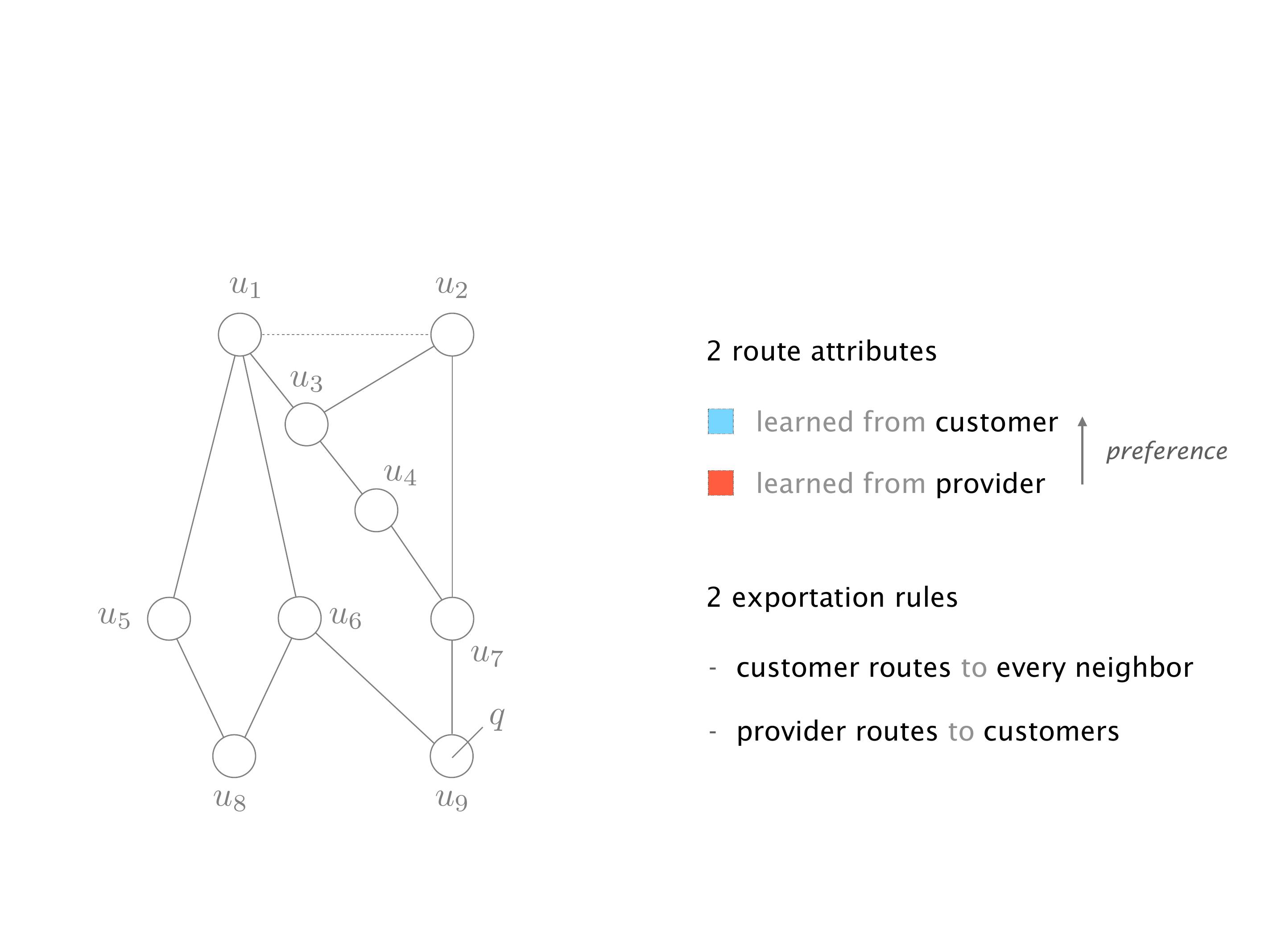
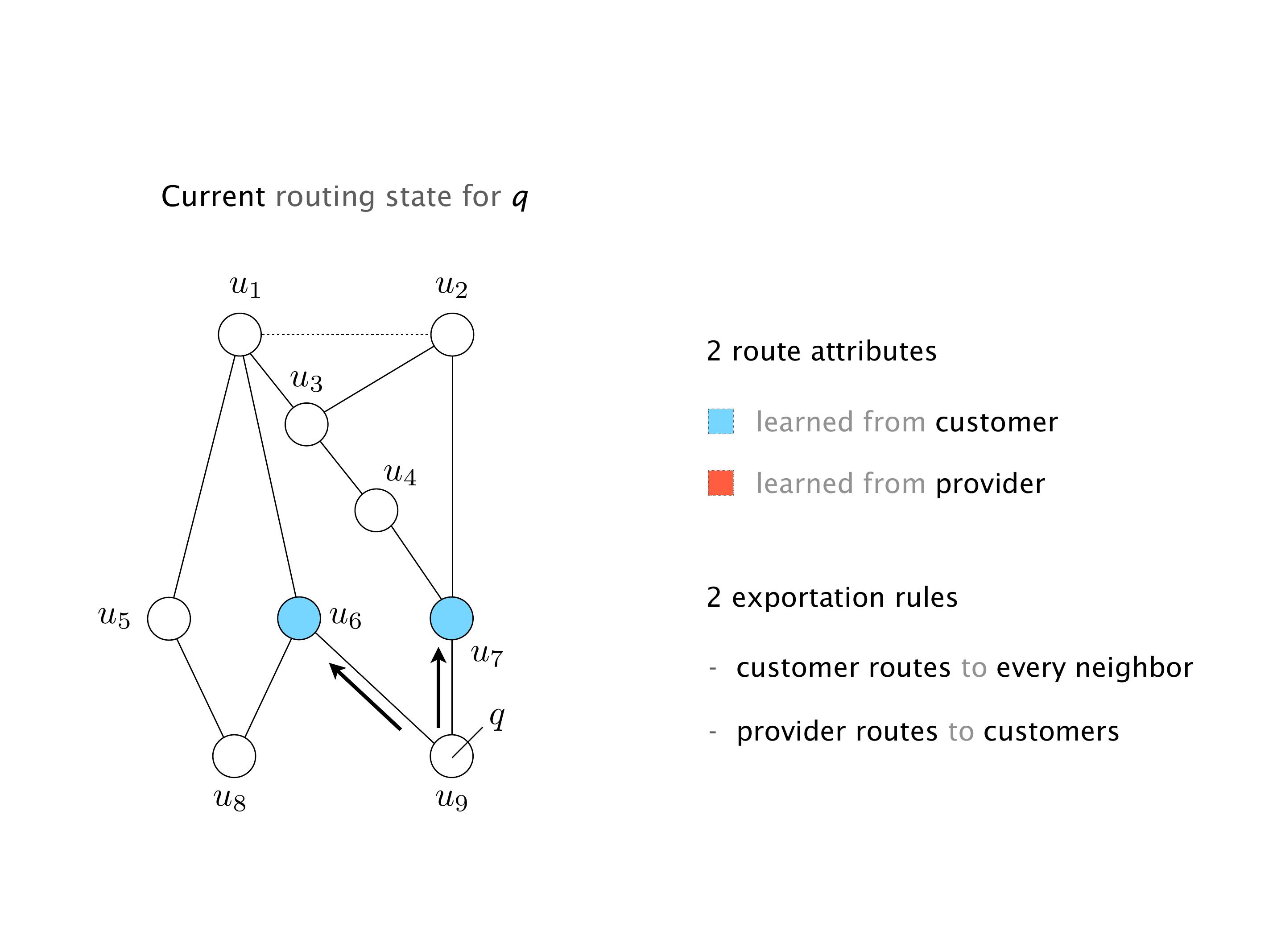
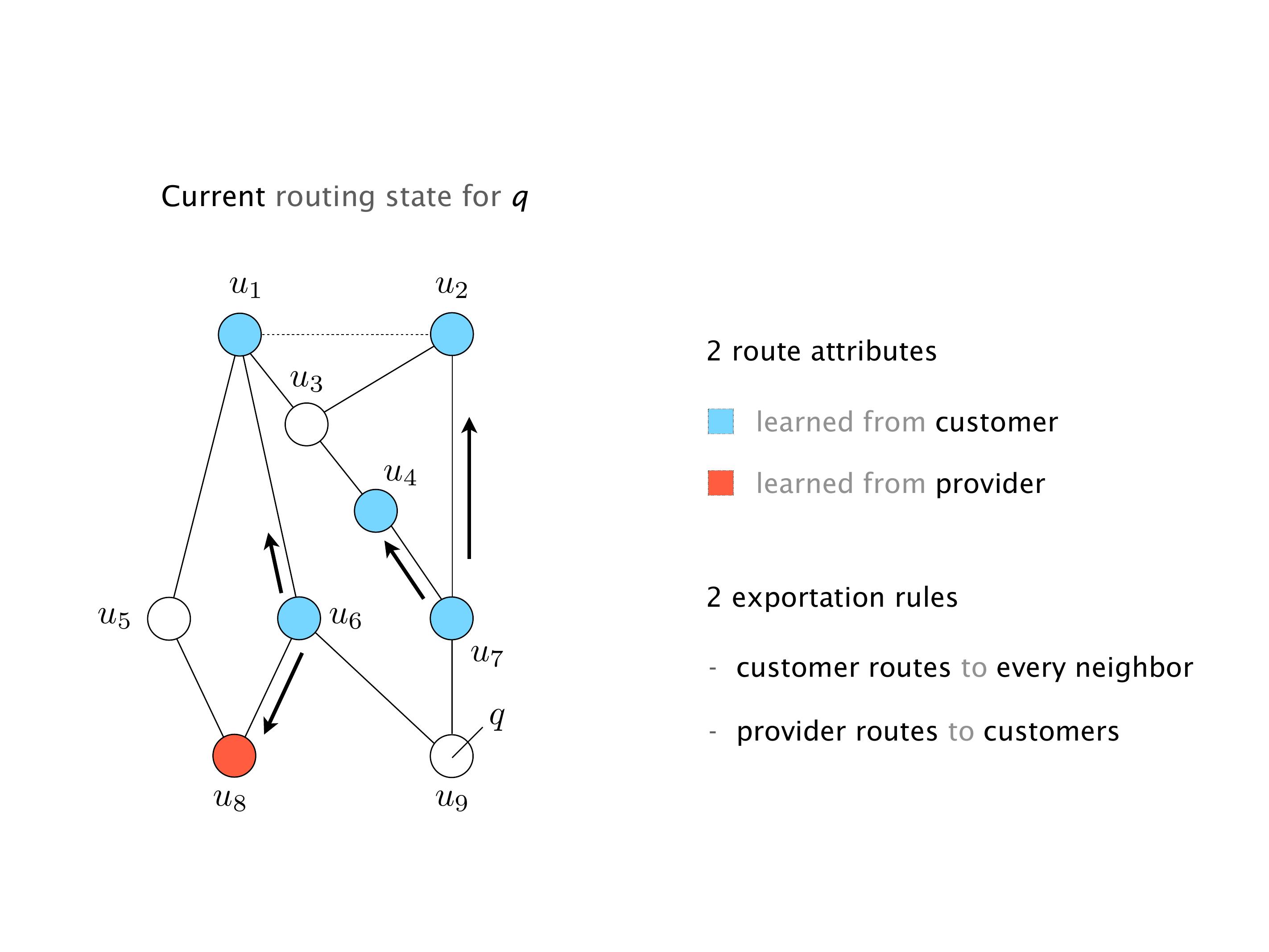
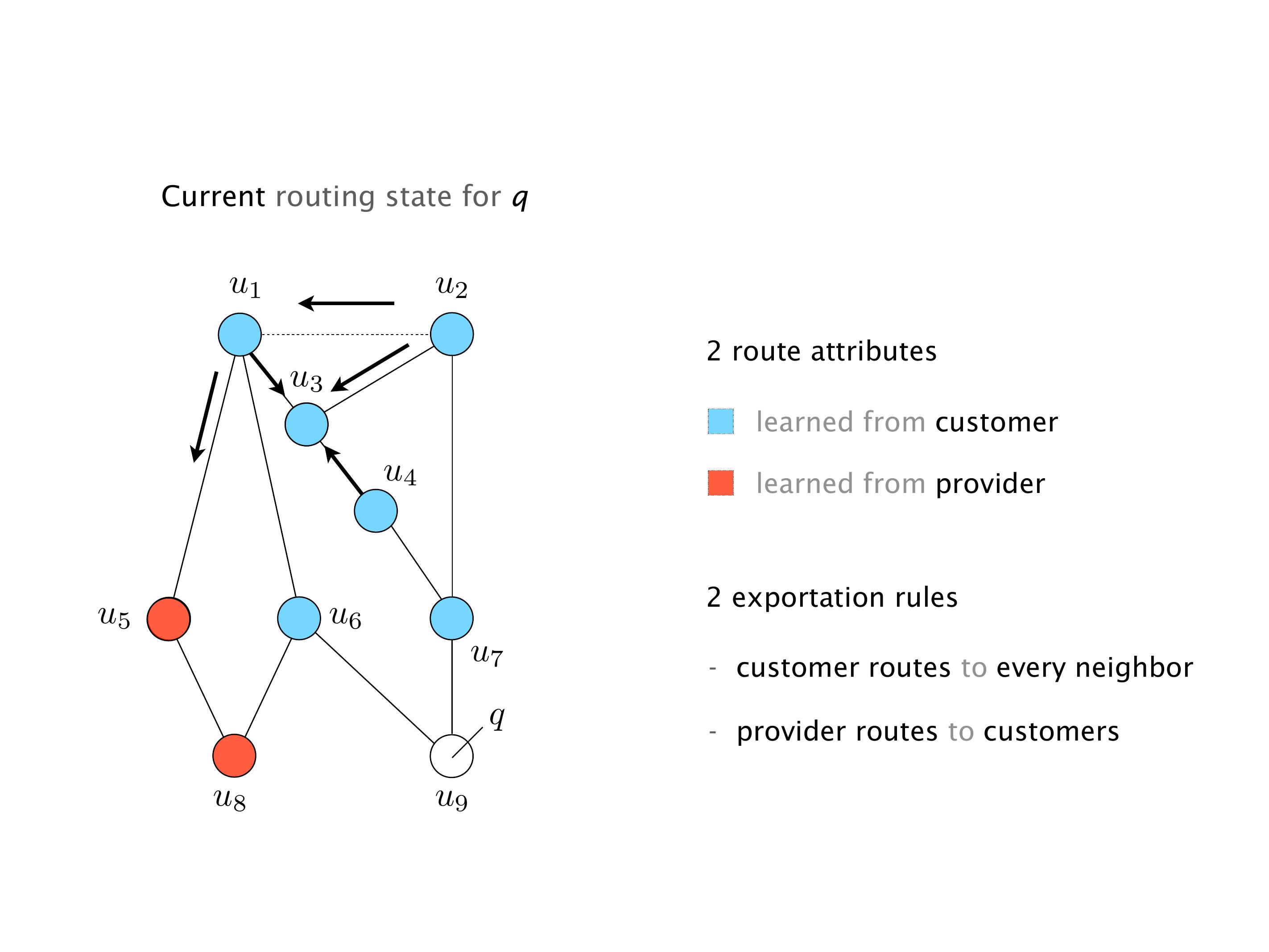
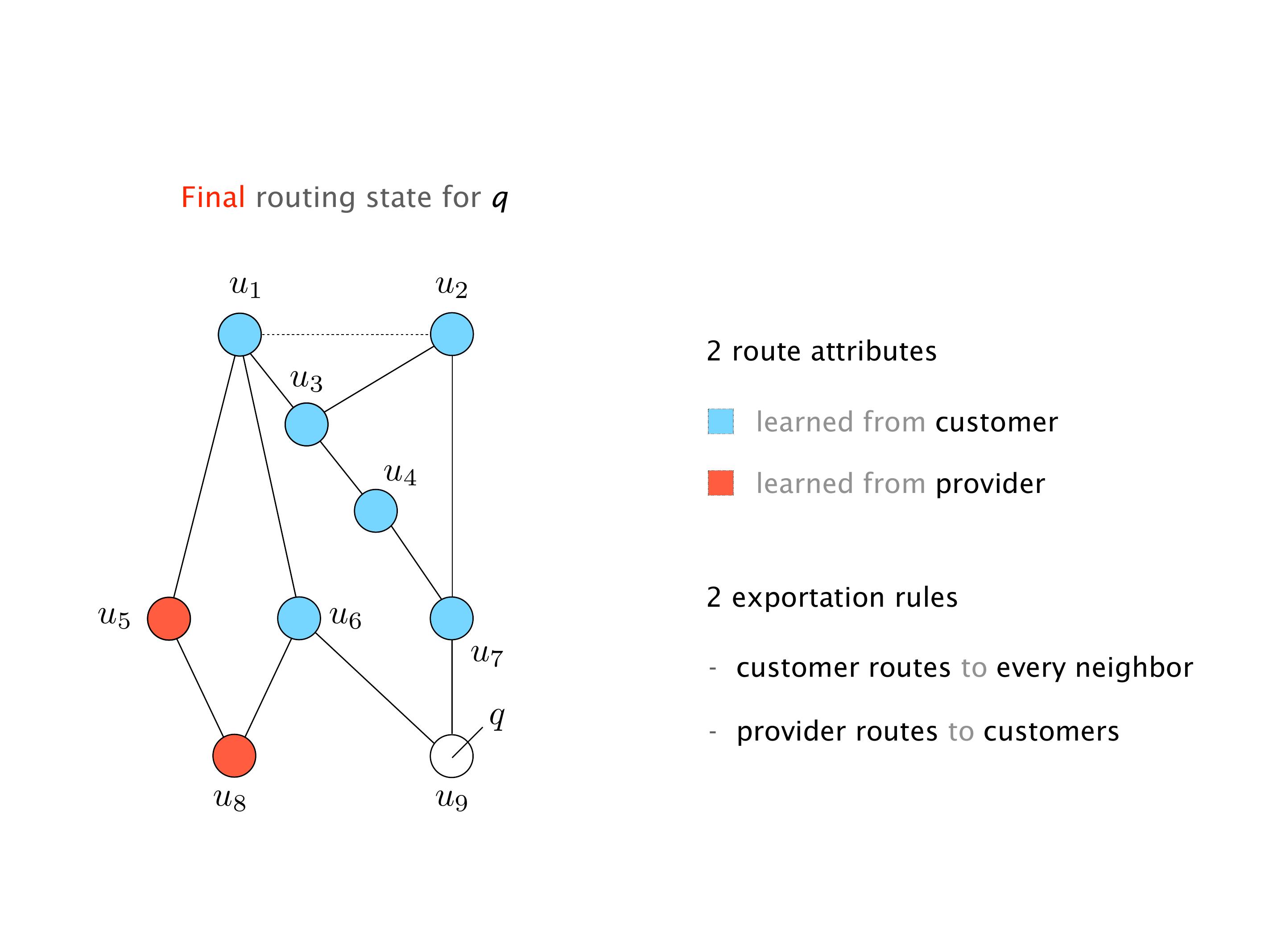
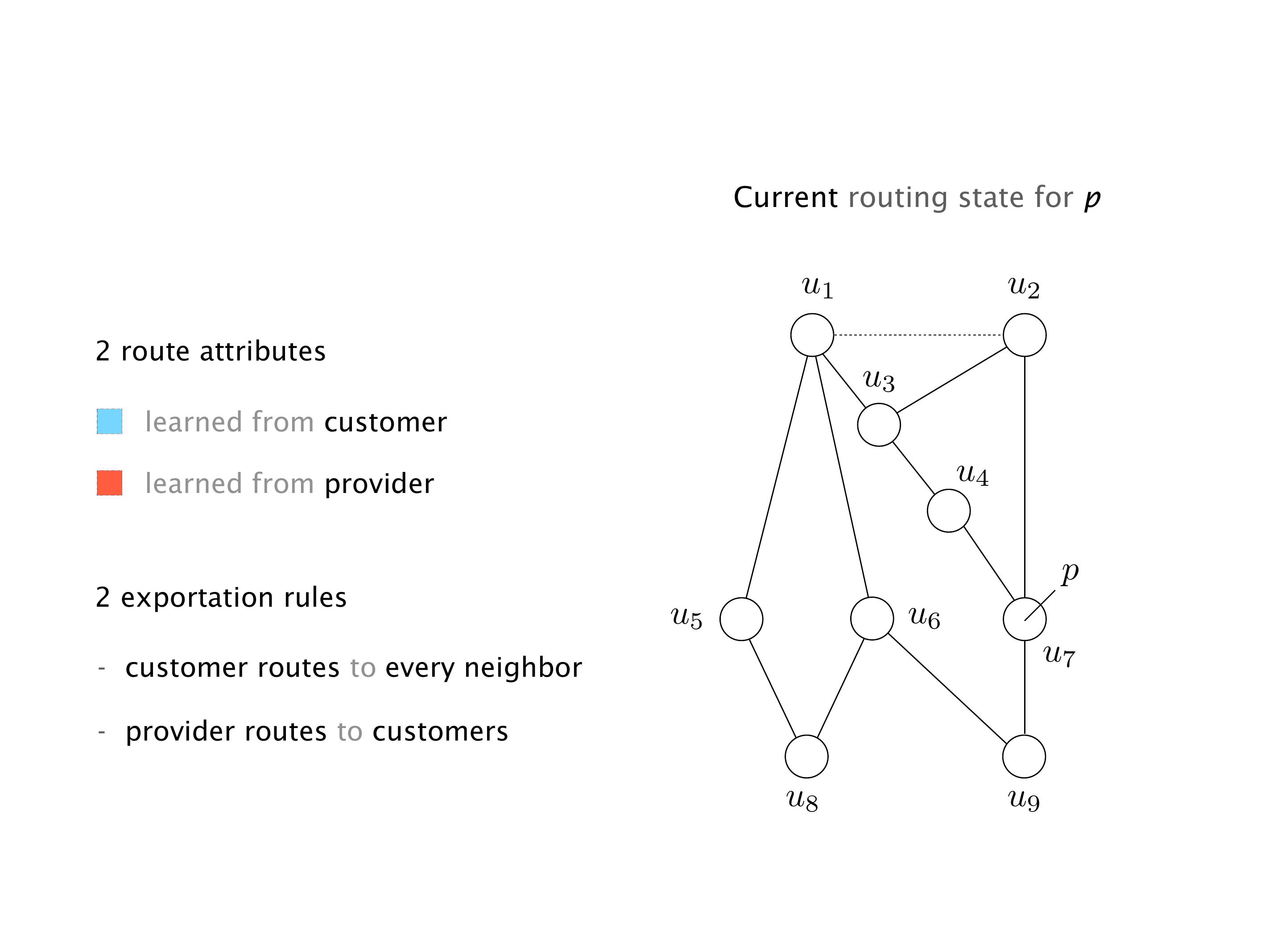
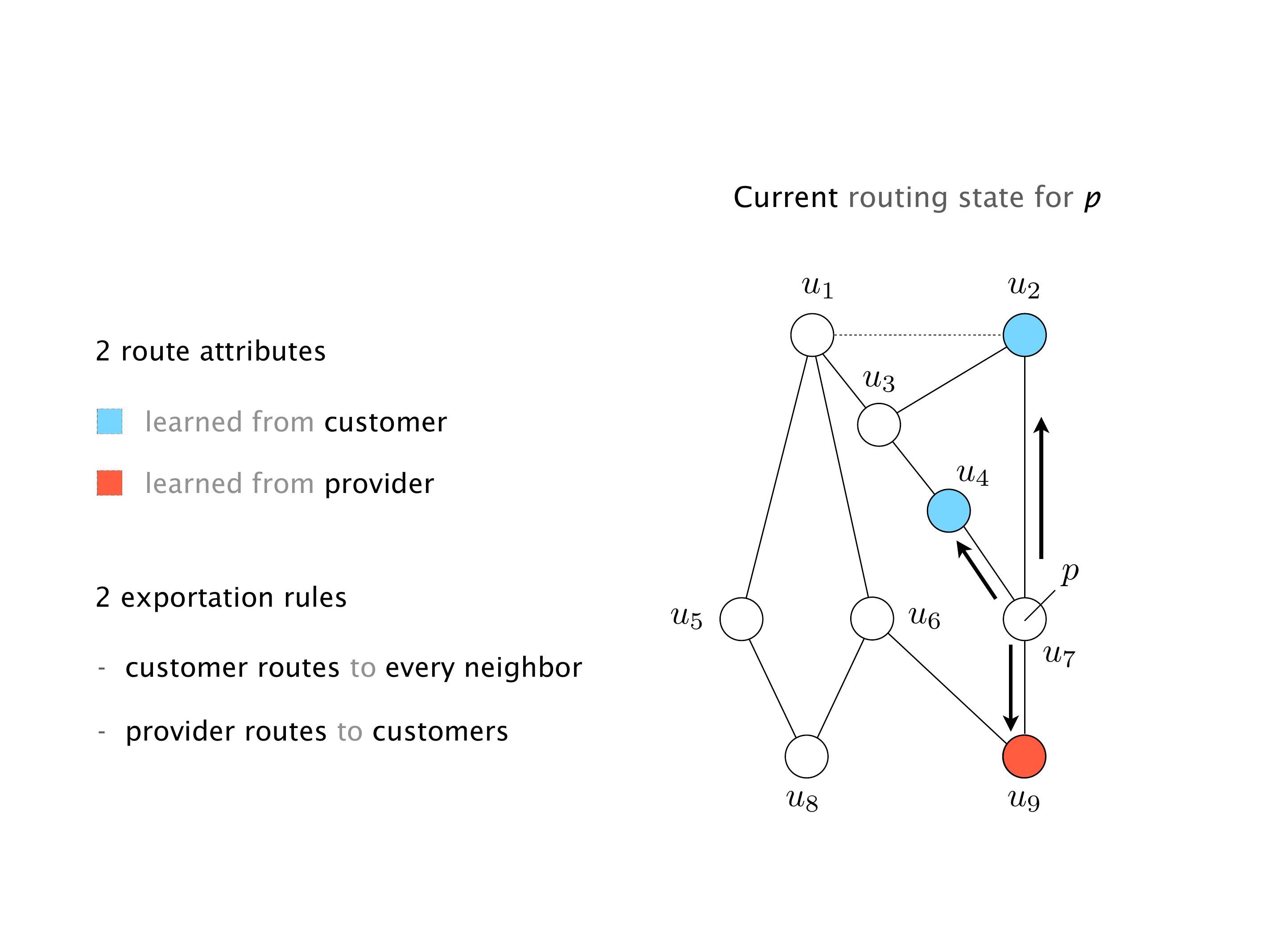
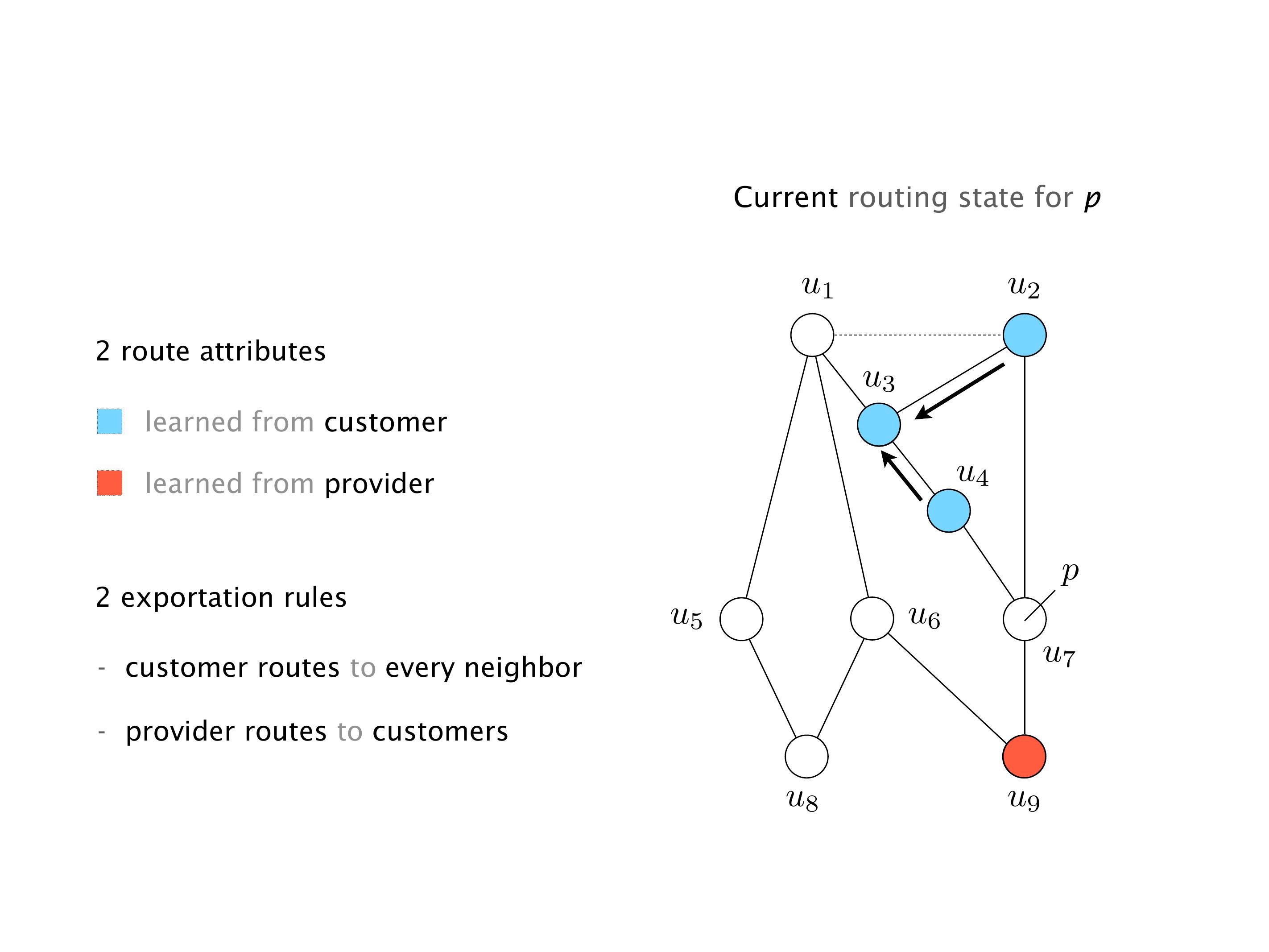
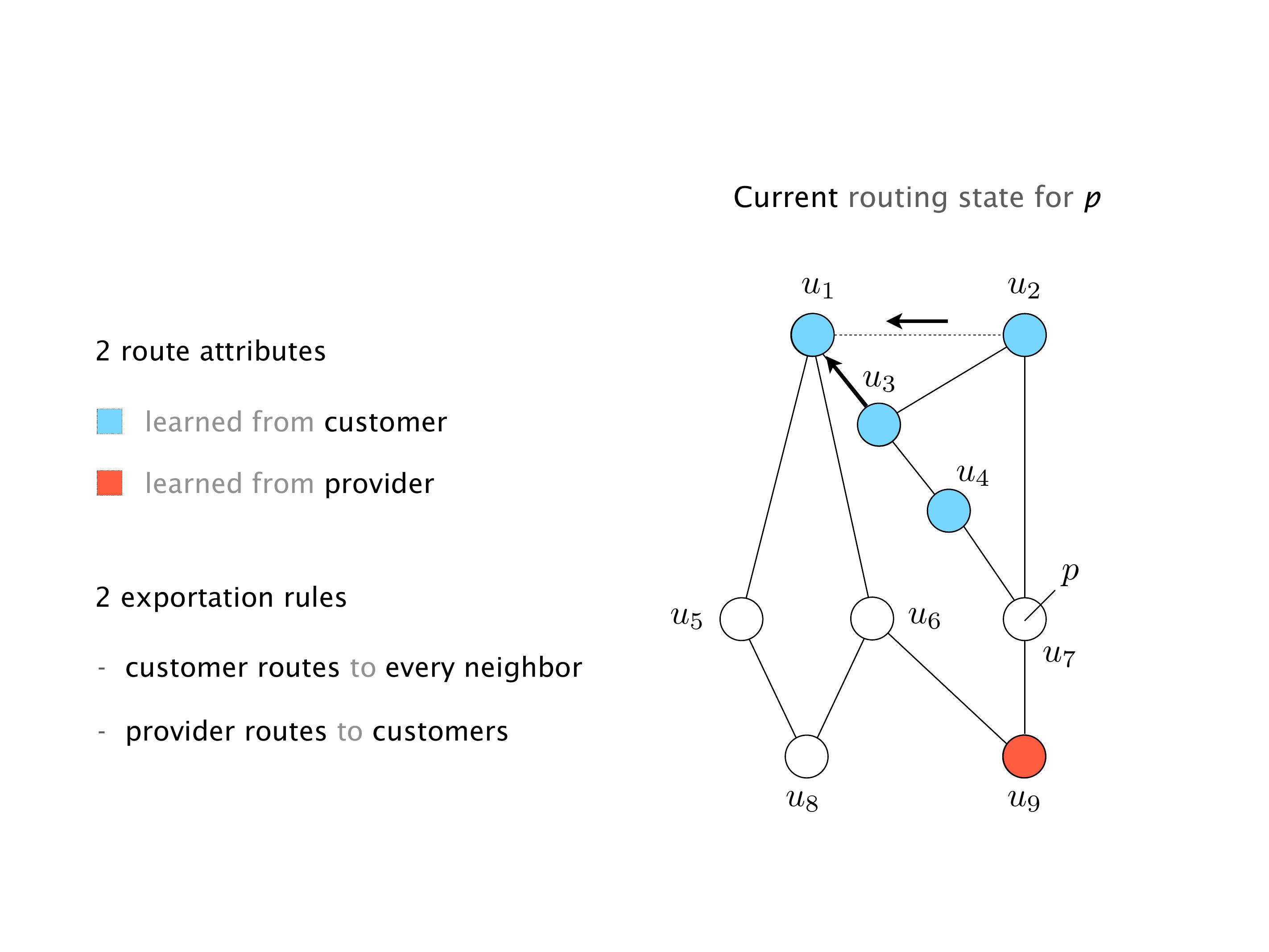
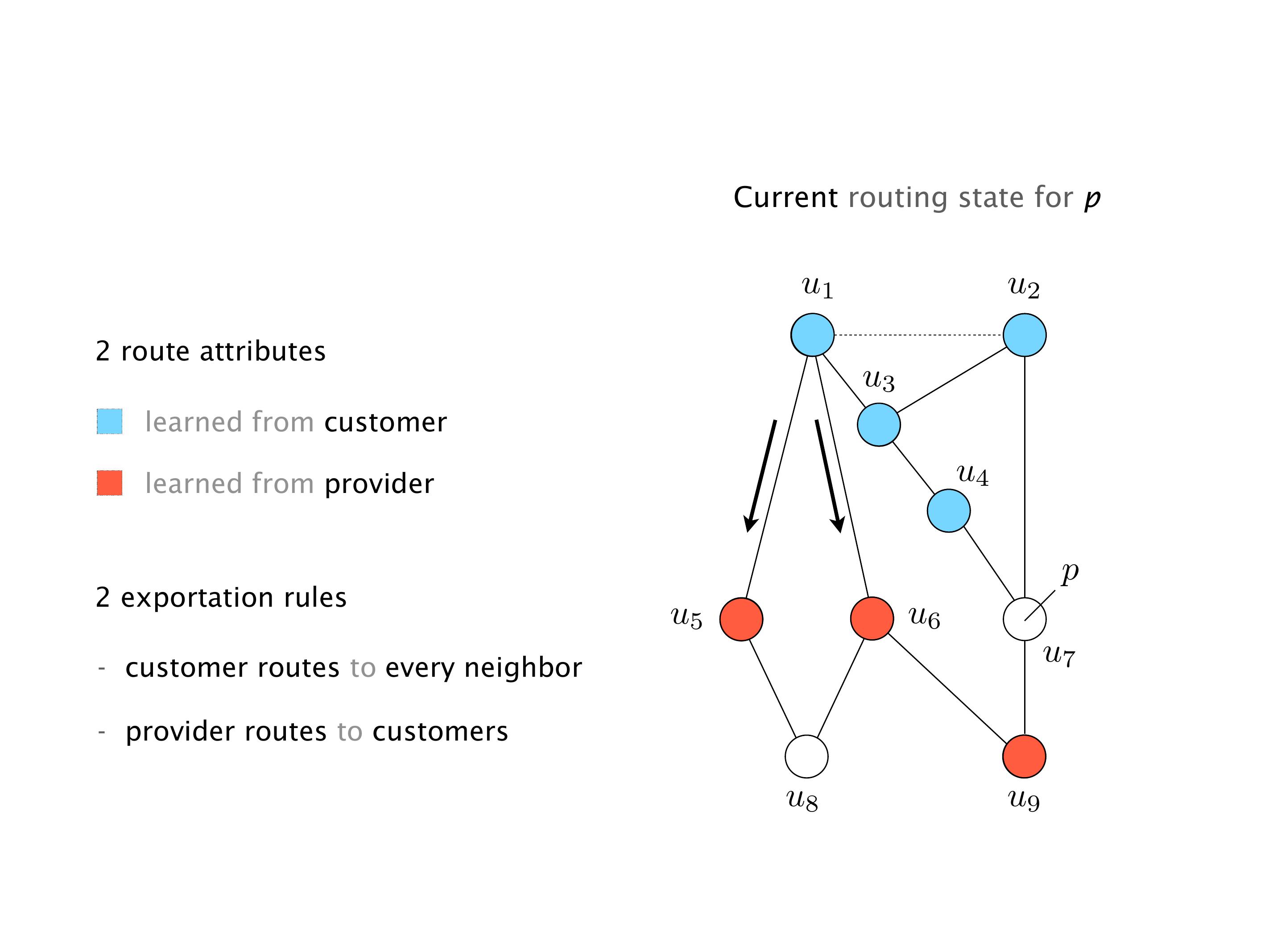
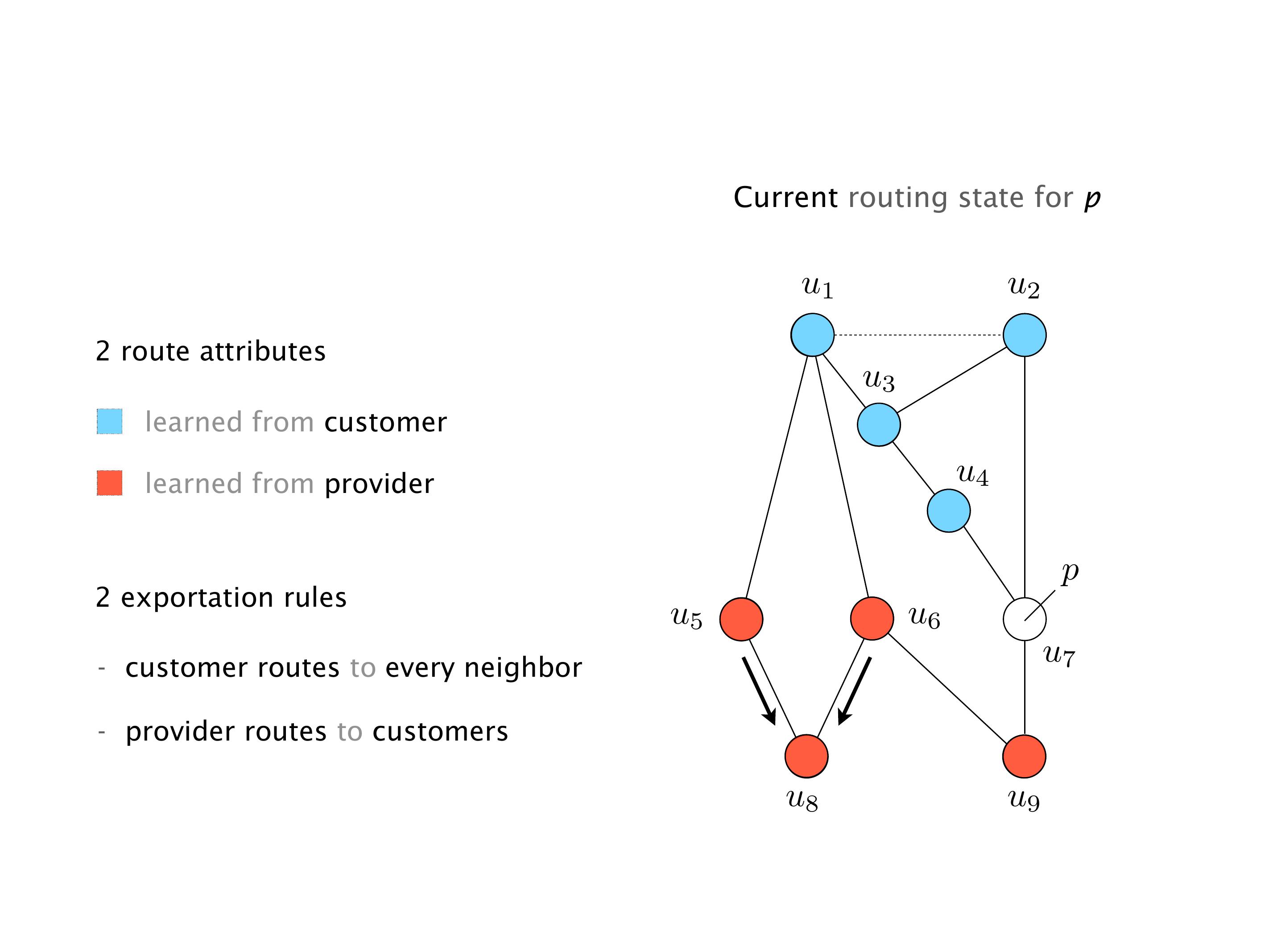
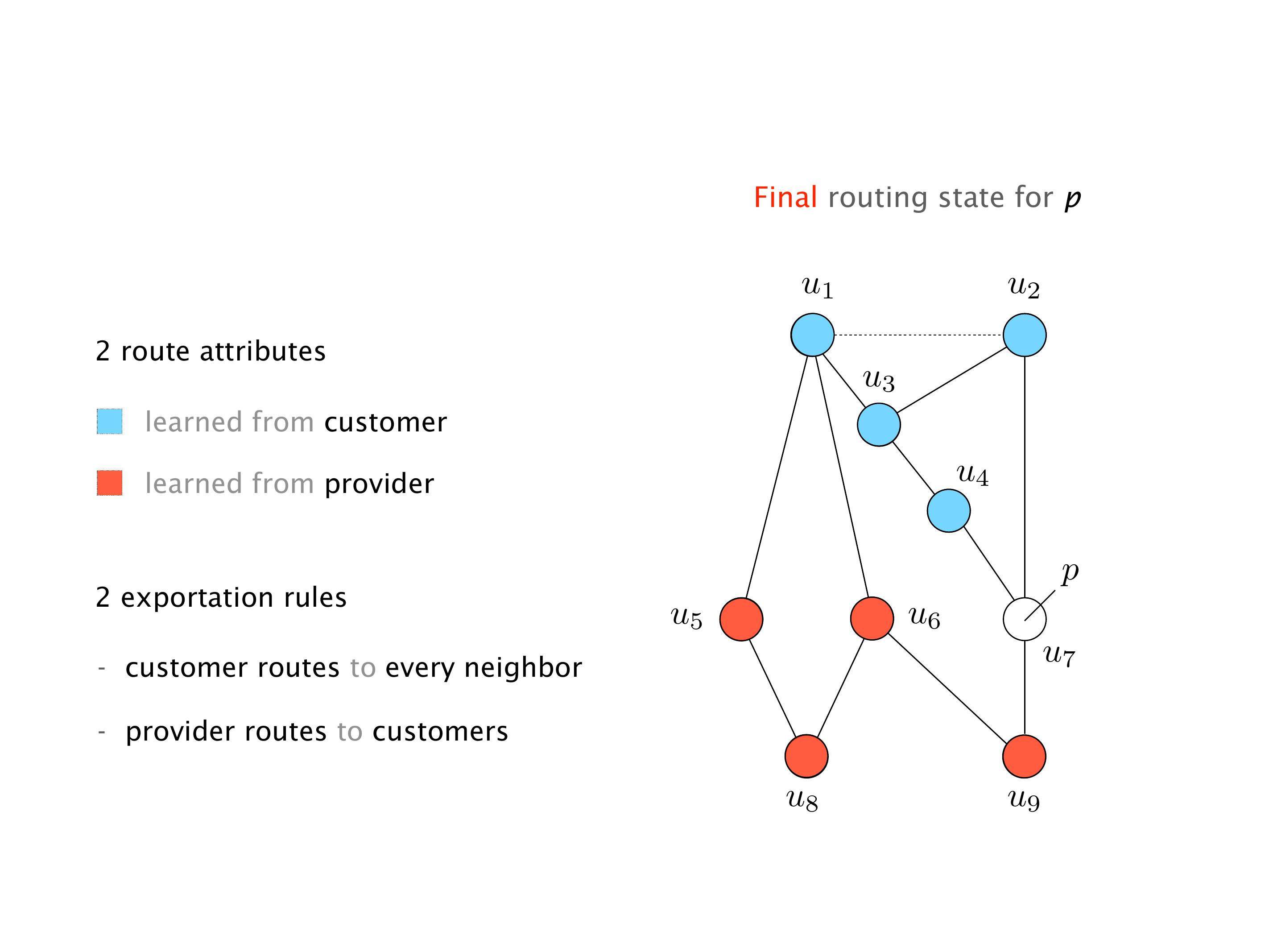
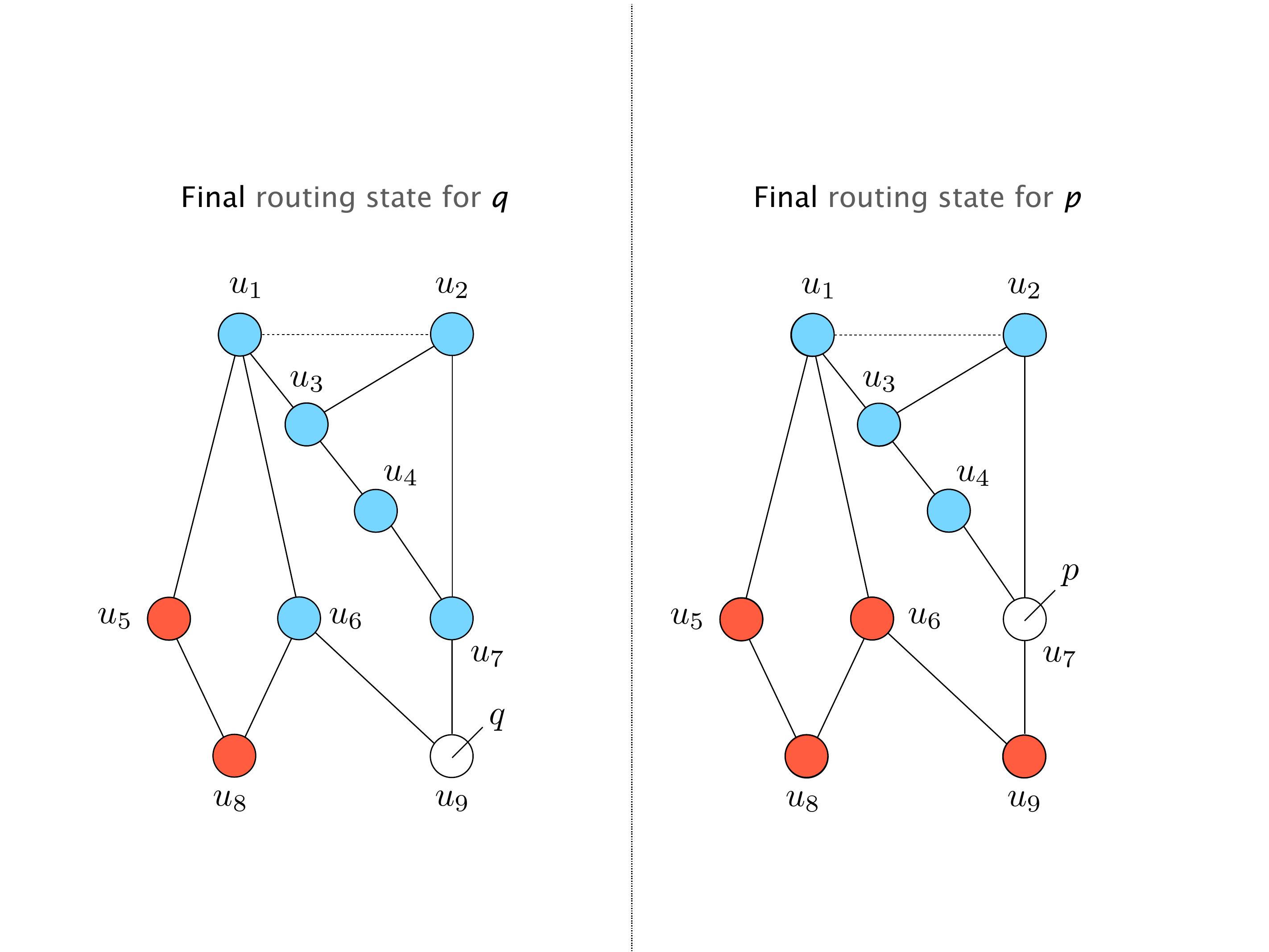
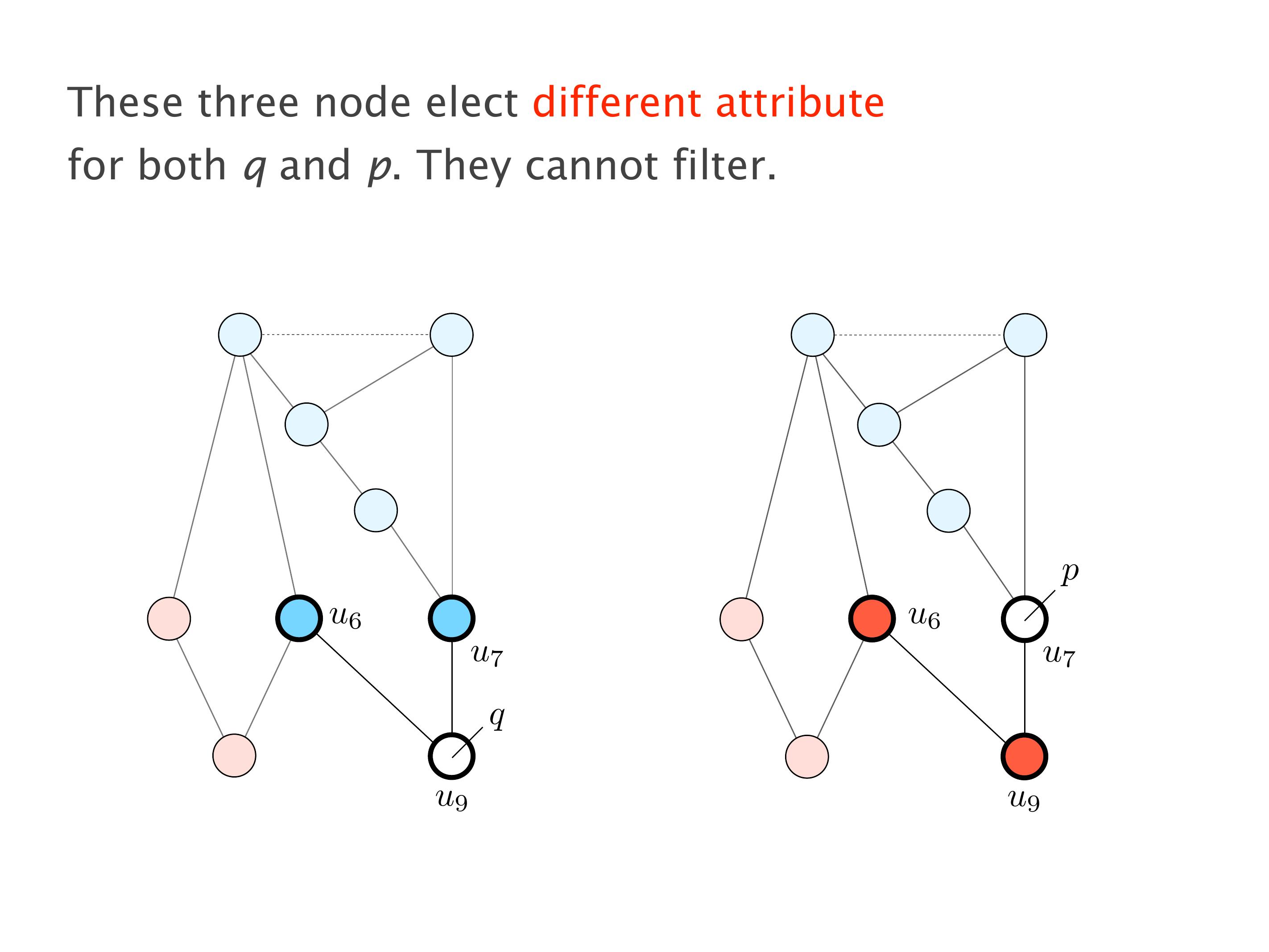
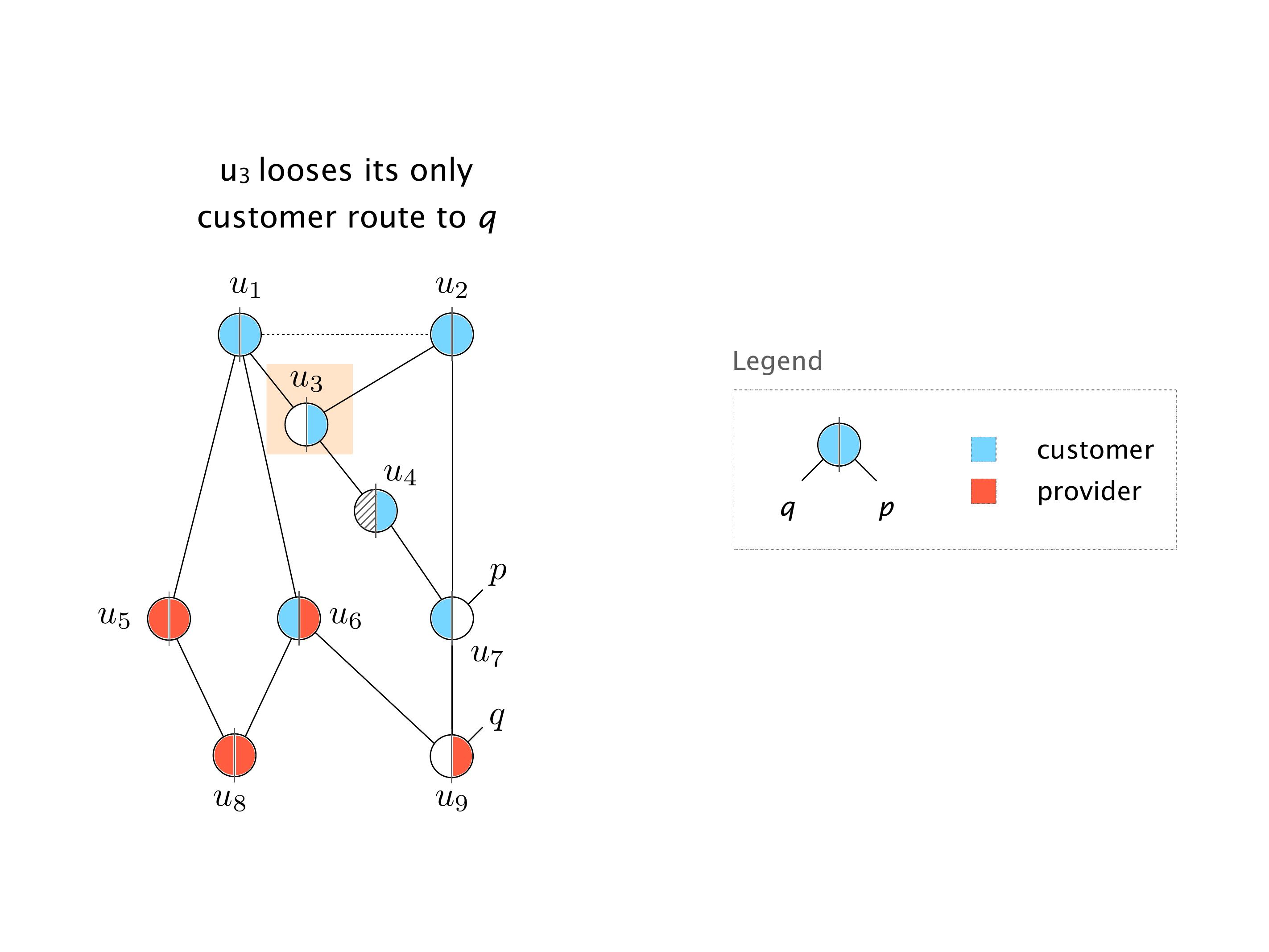
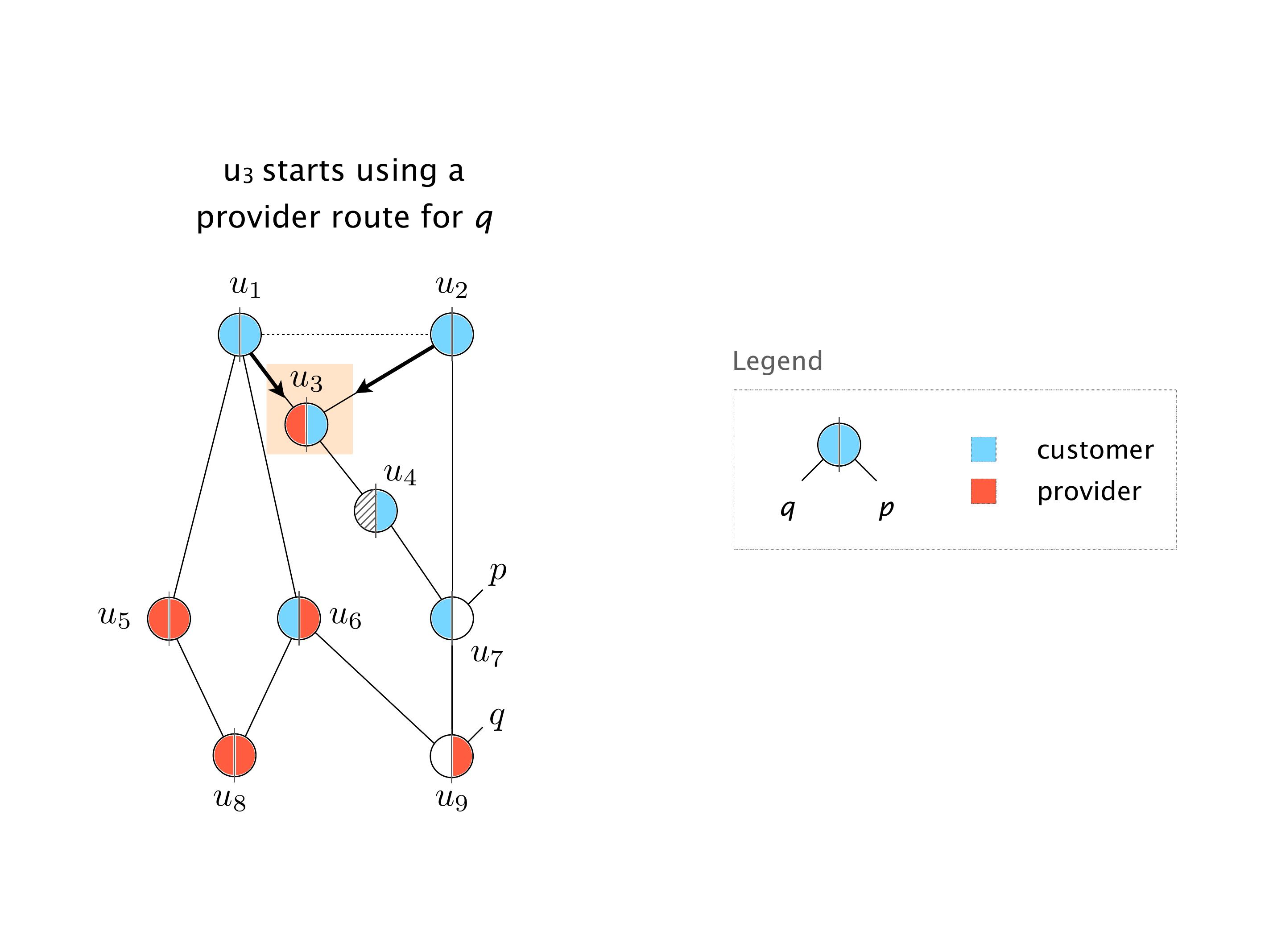
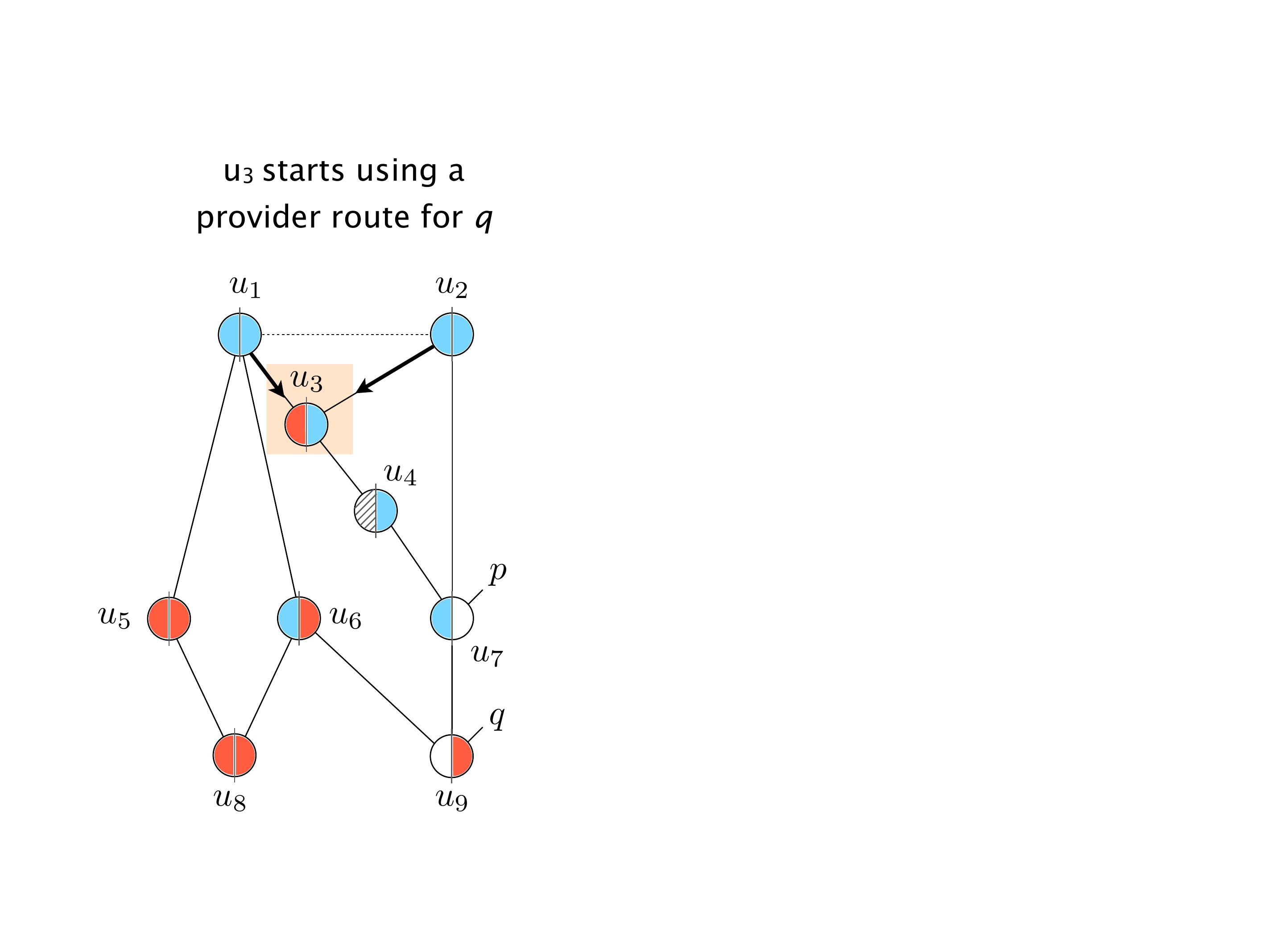
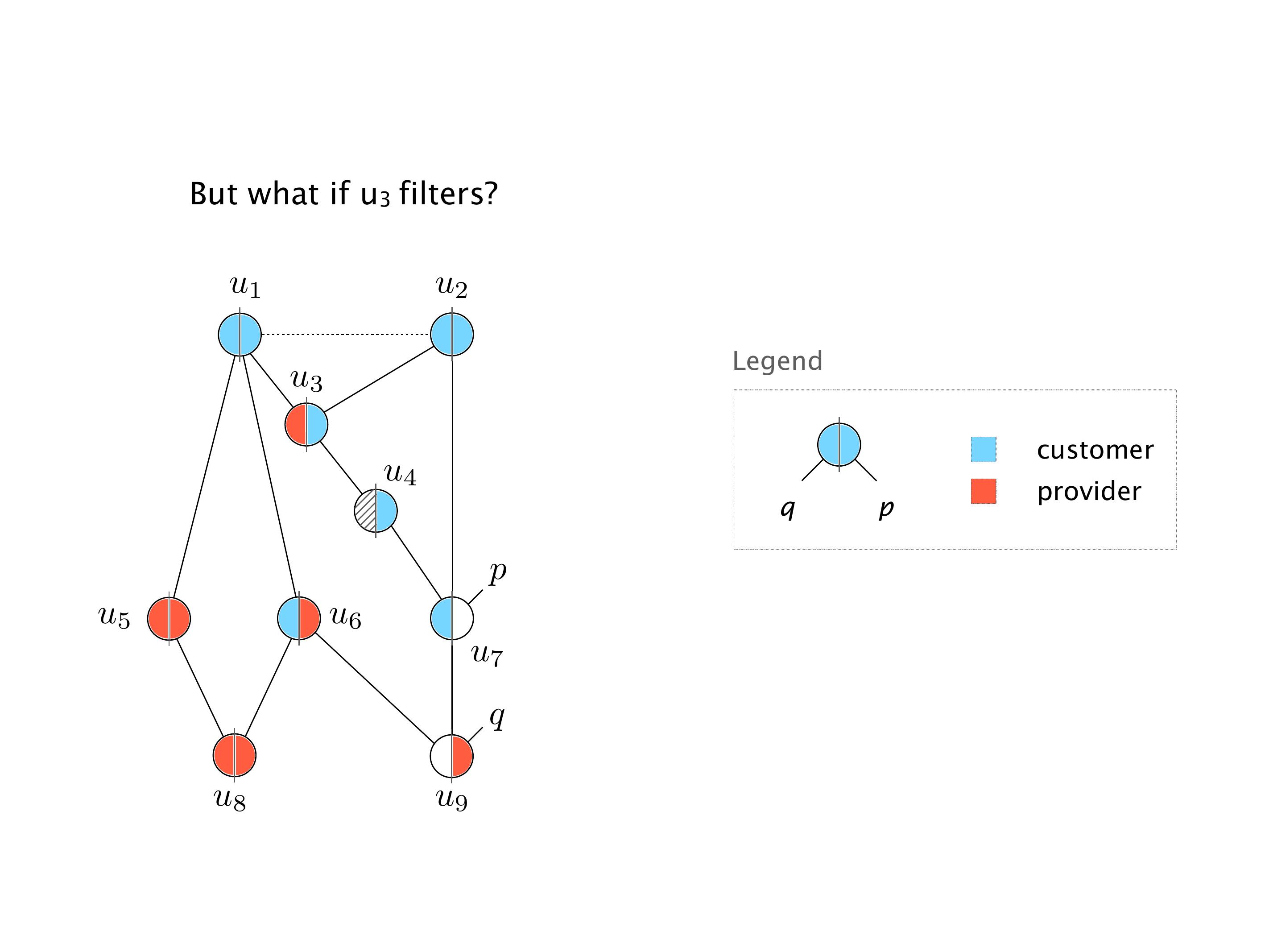
Another example of anomalies at scale are permanent oscillations. So again, this is a little bit of a crazy network, but I'll just give you one example where it happens.
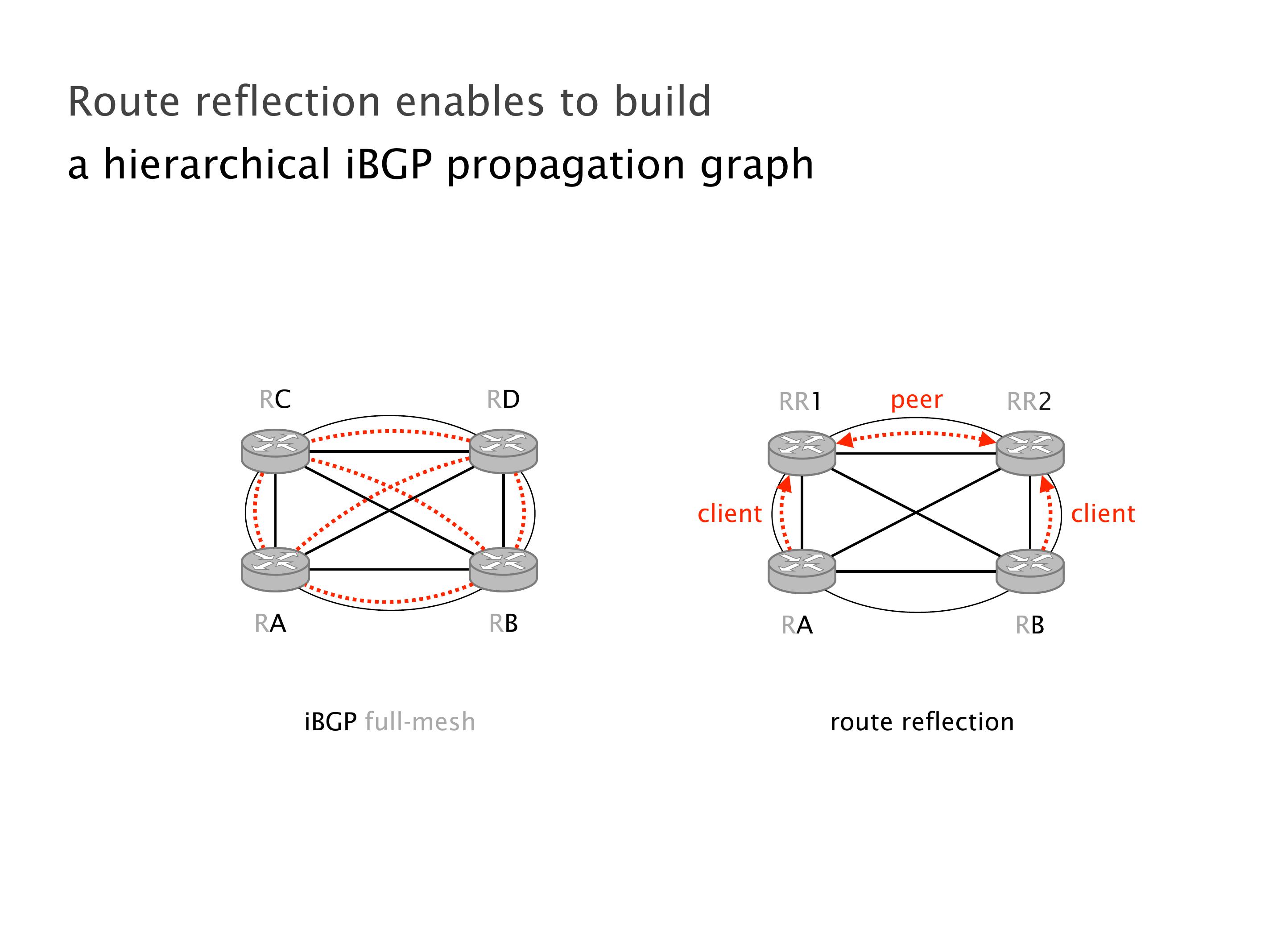
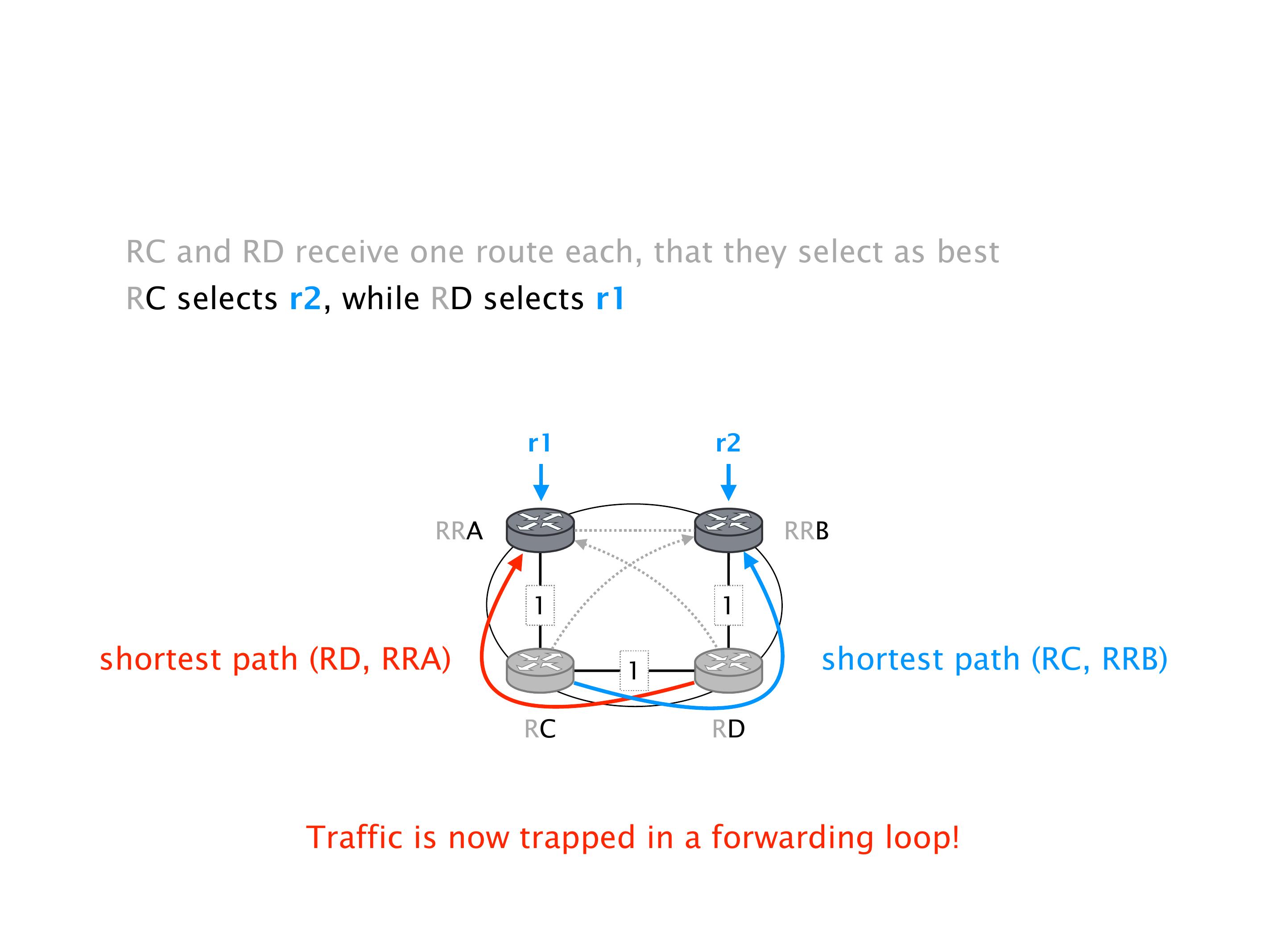
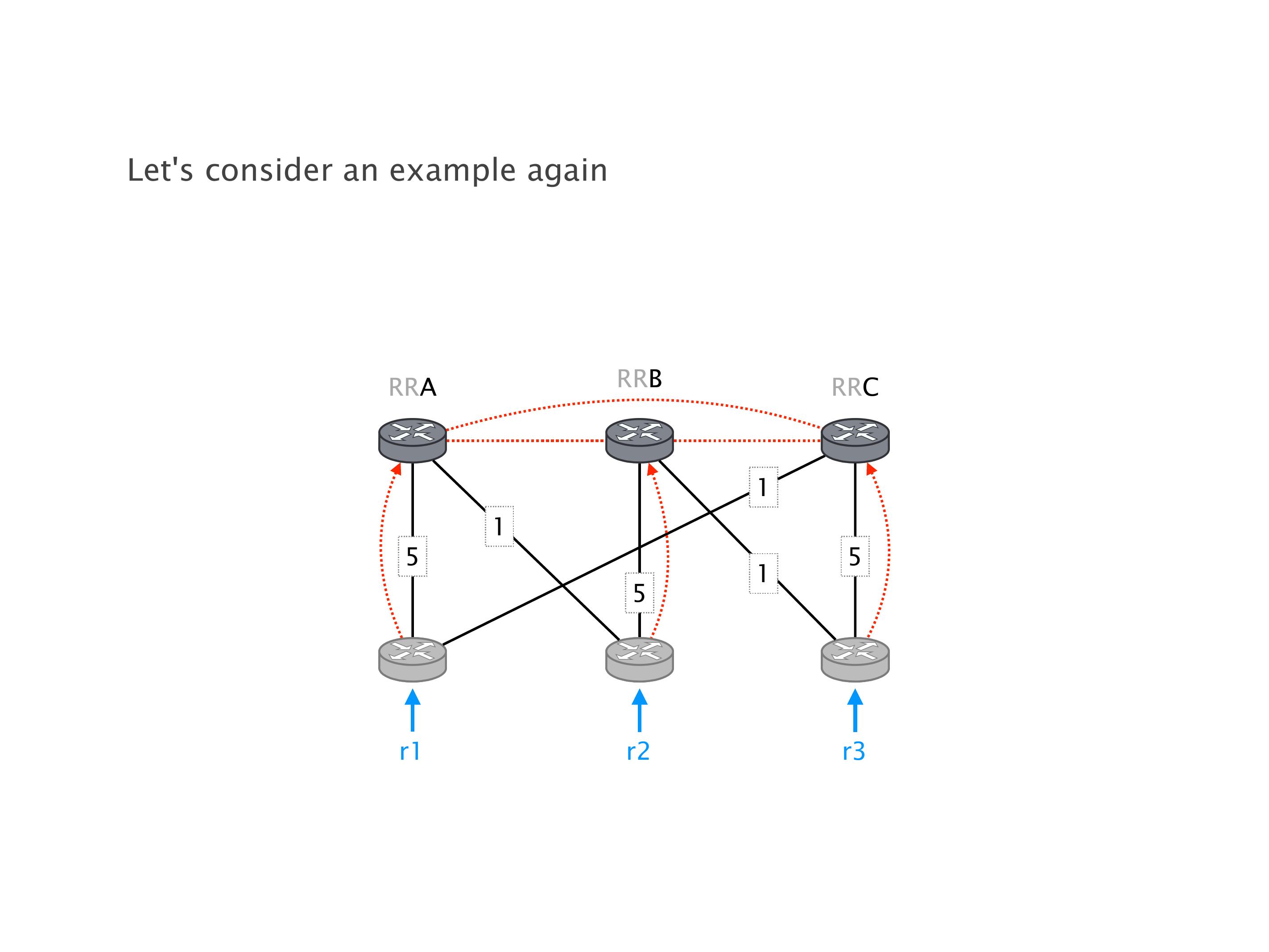
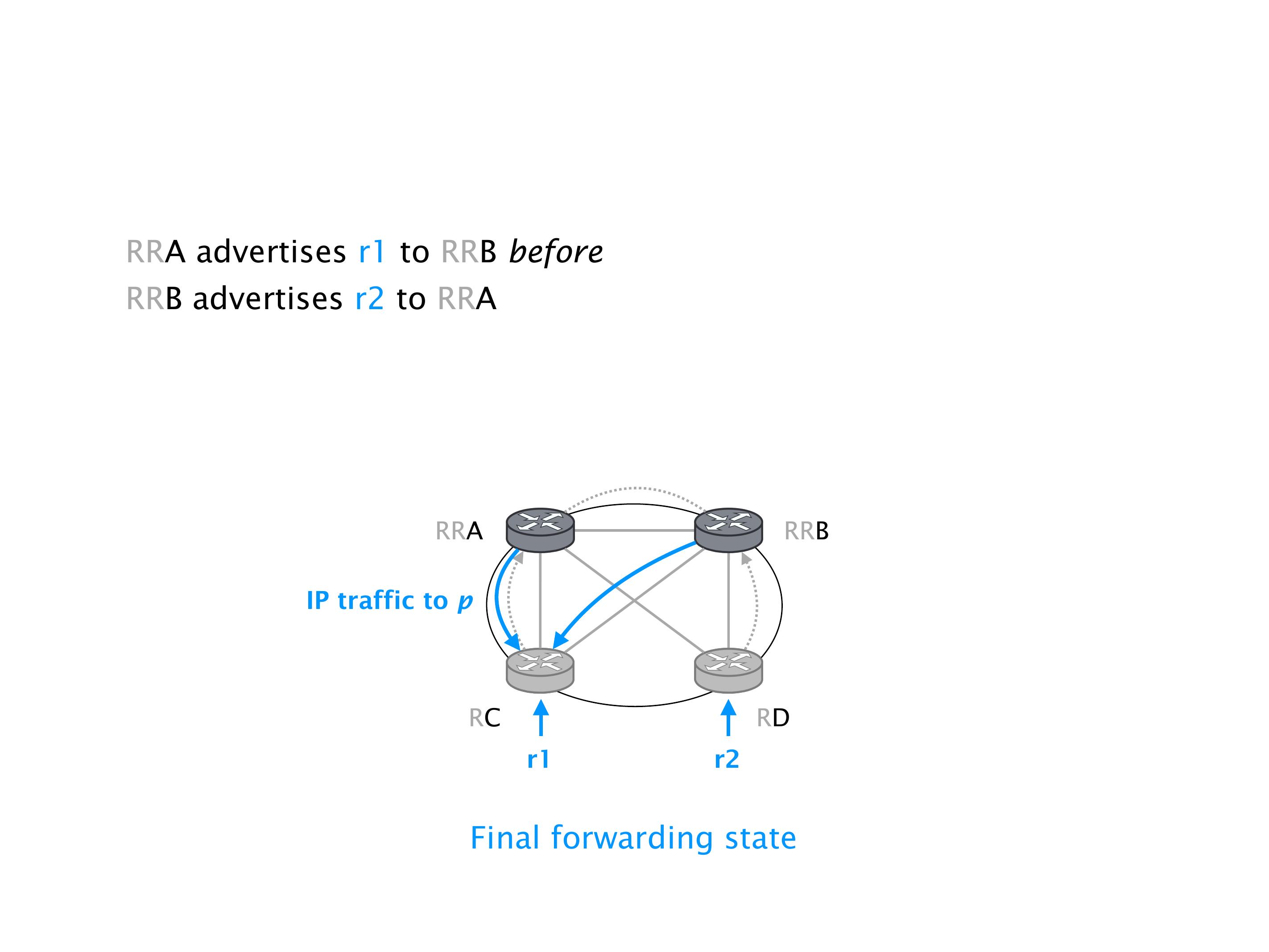
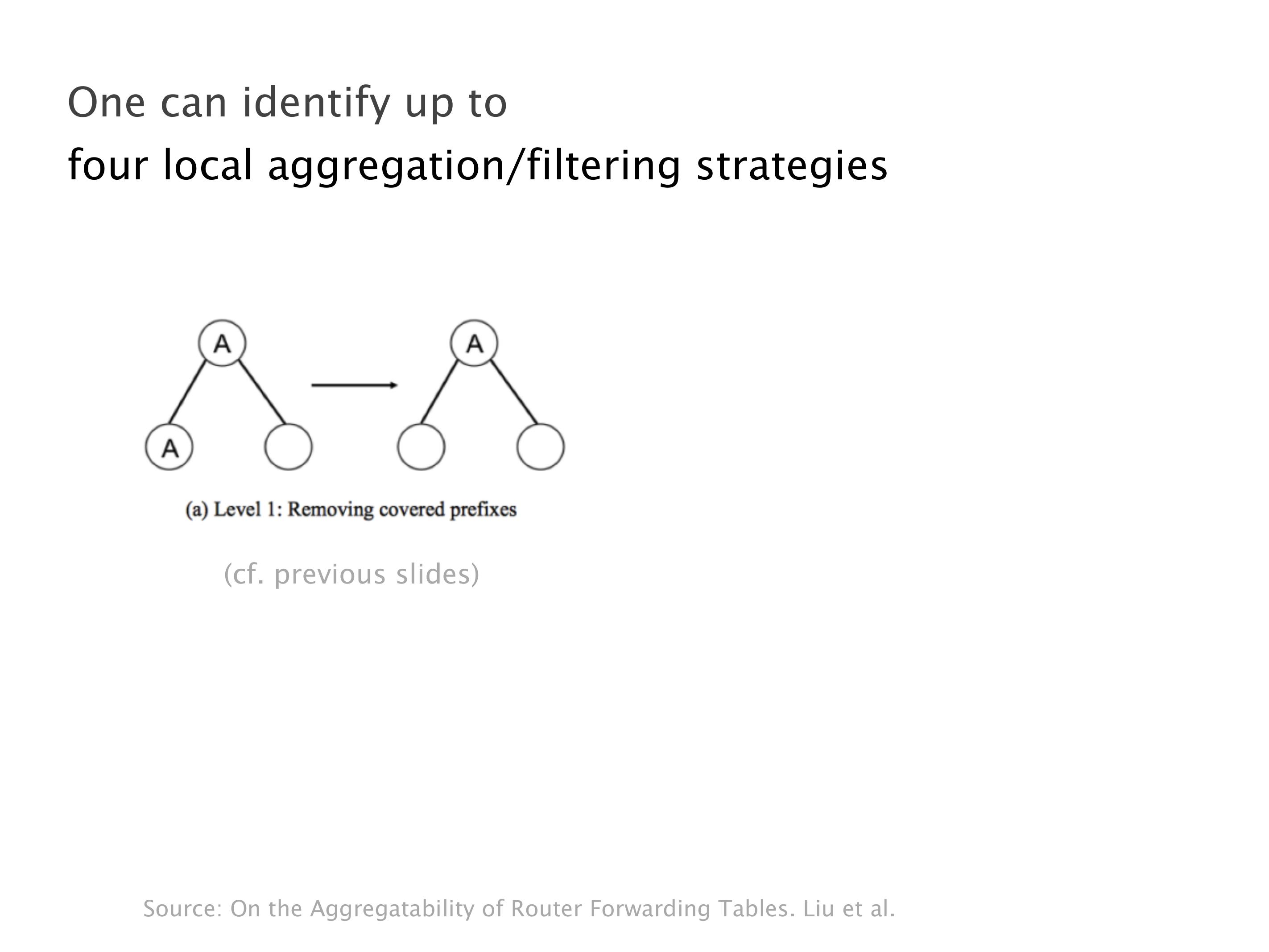
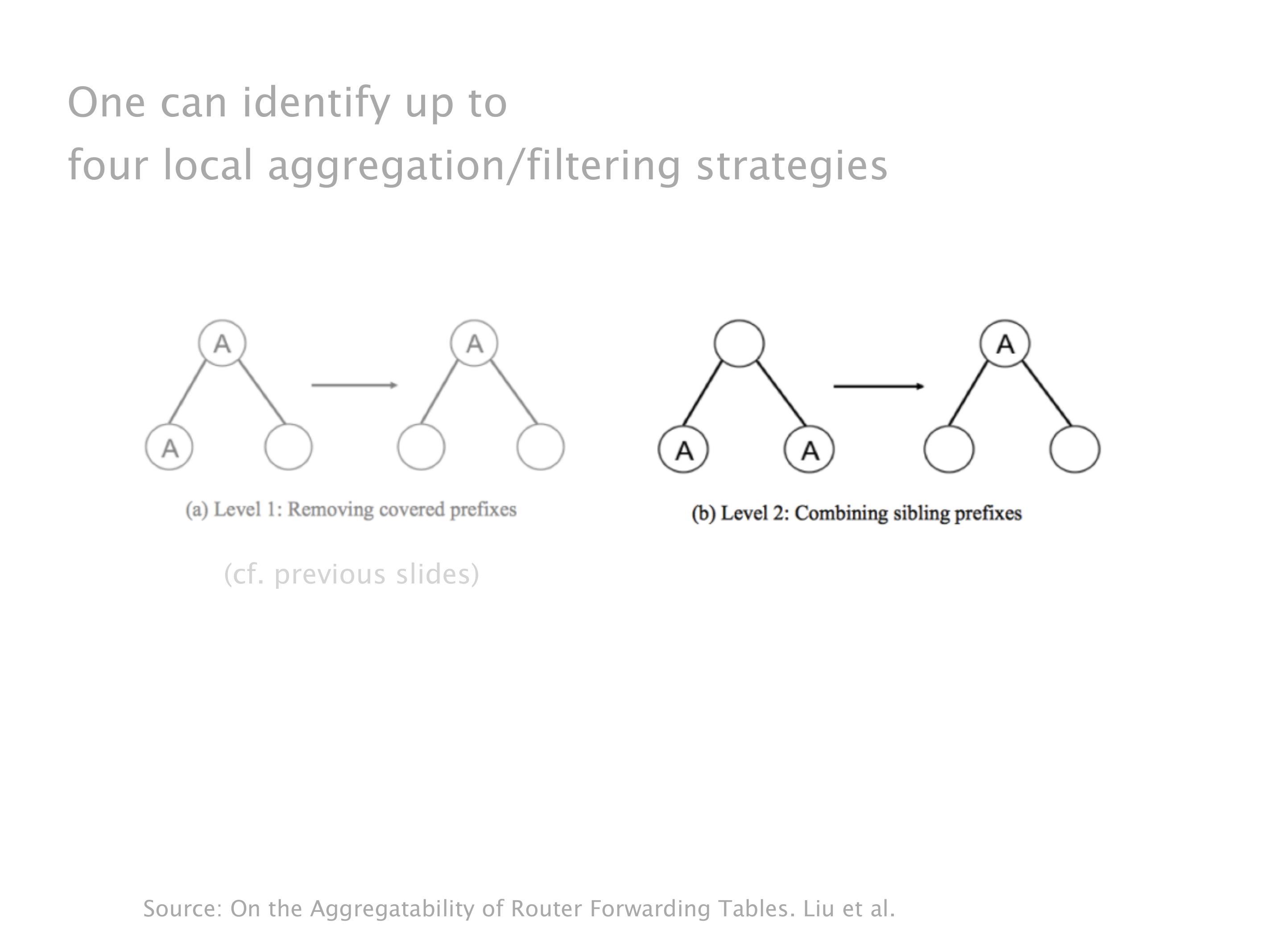
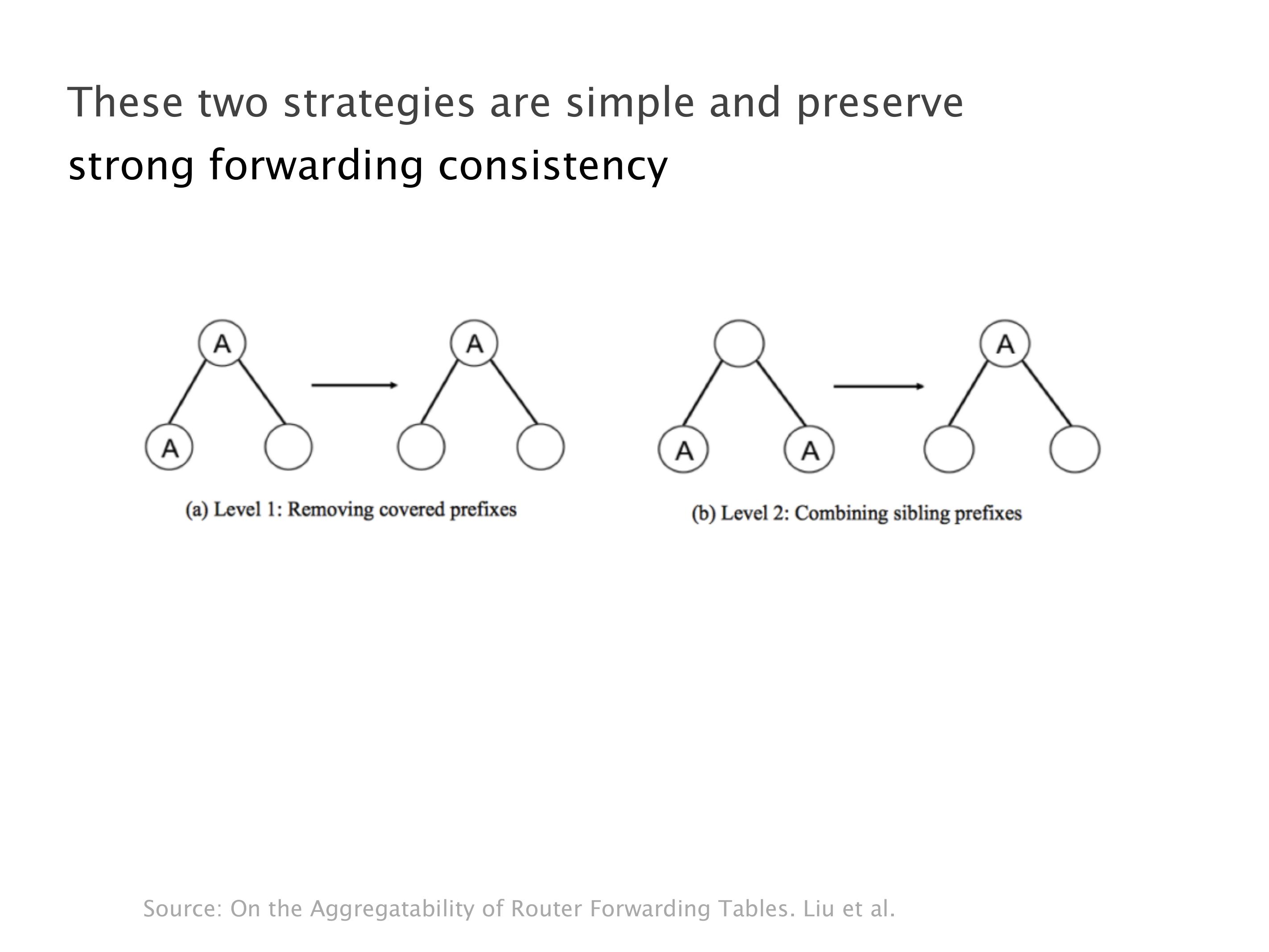
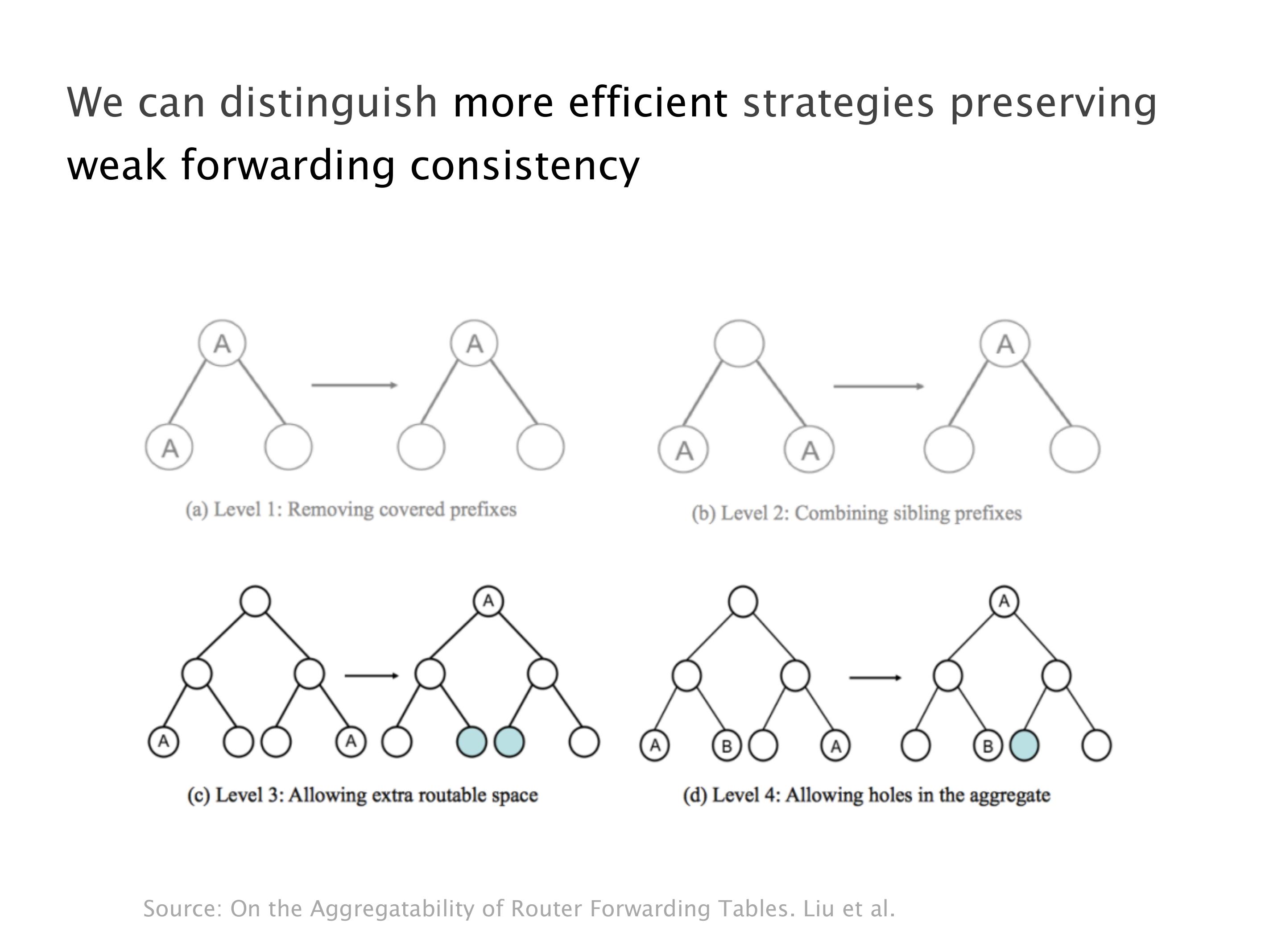
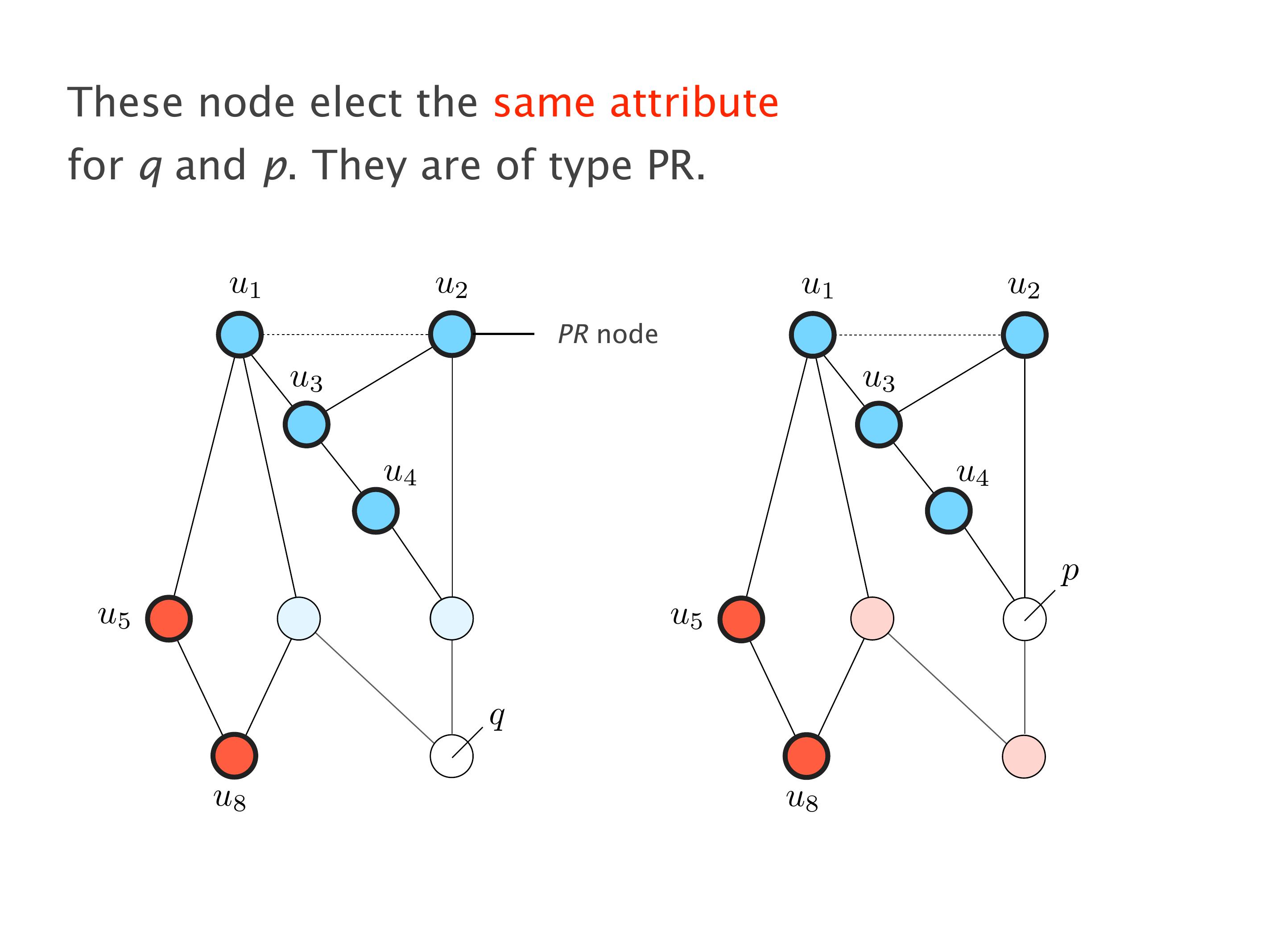
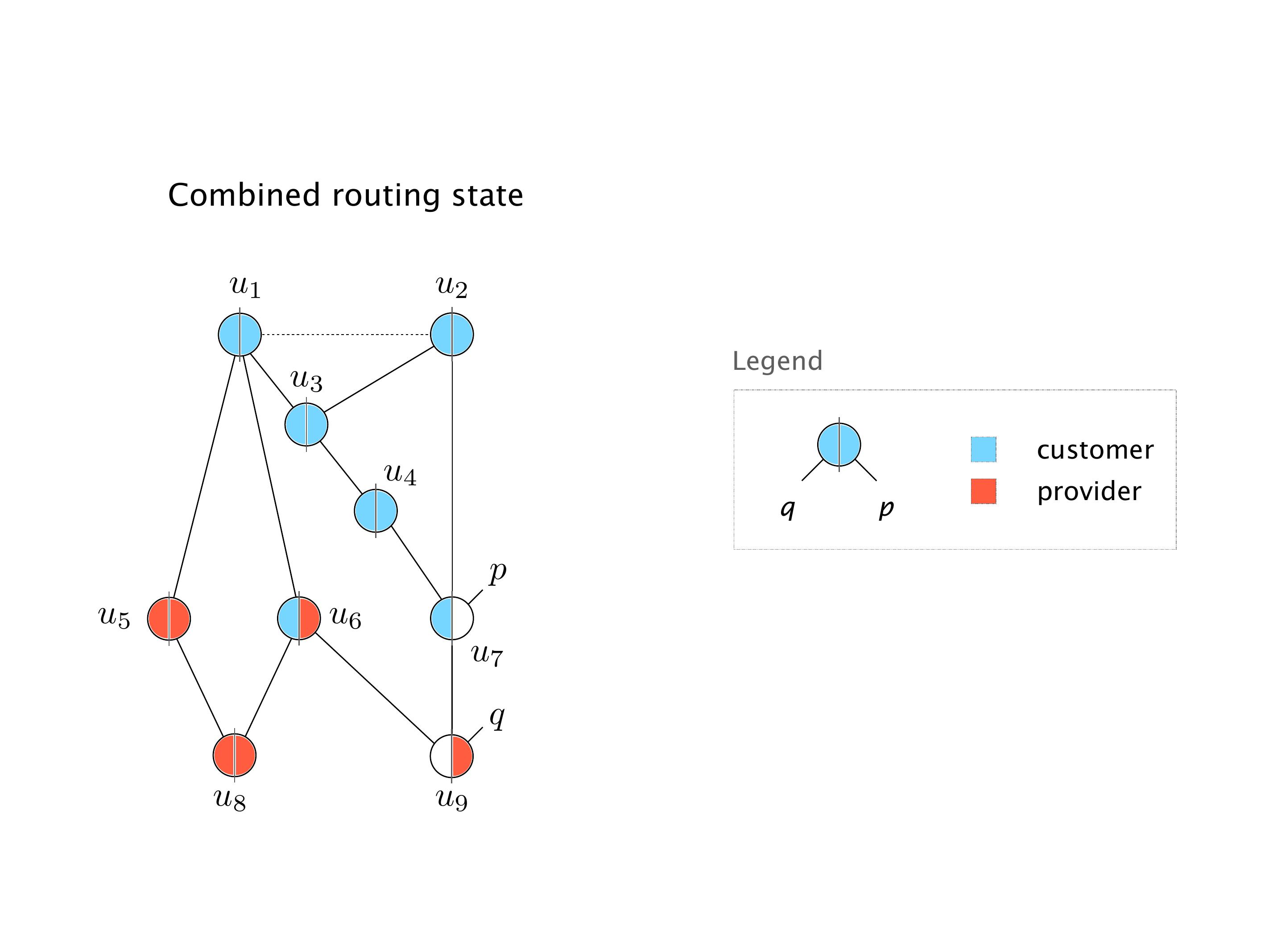
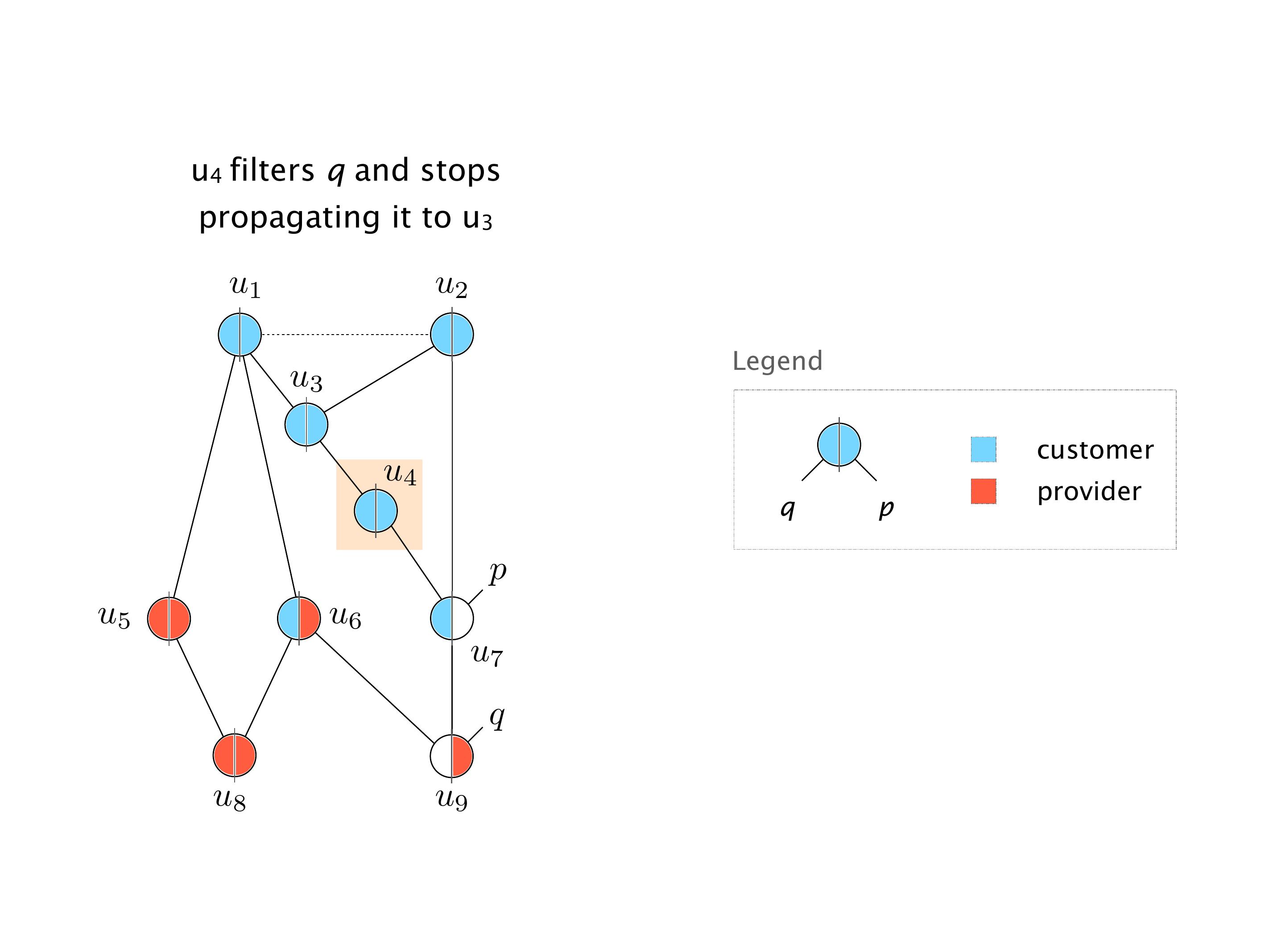
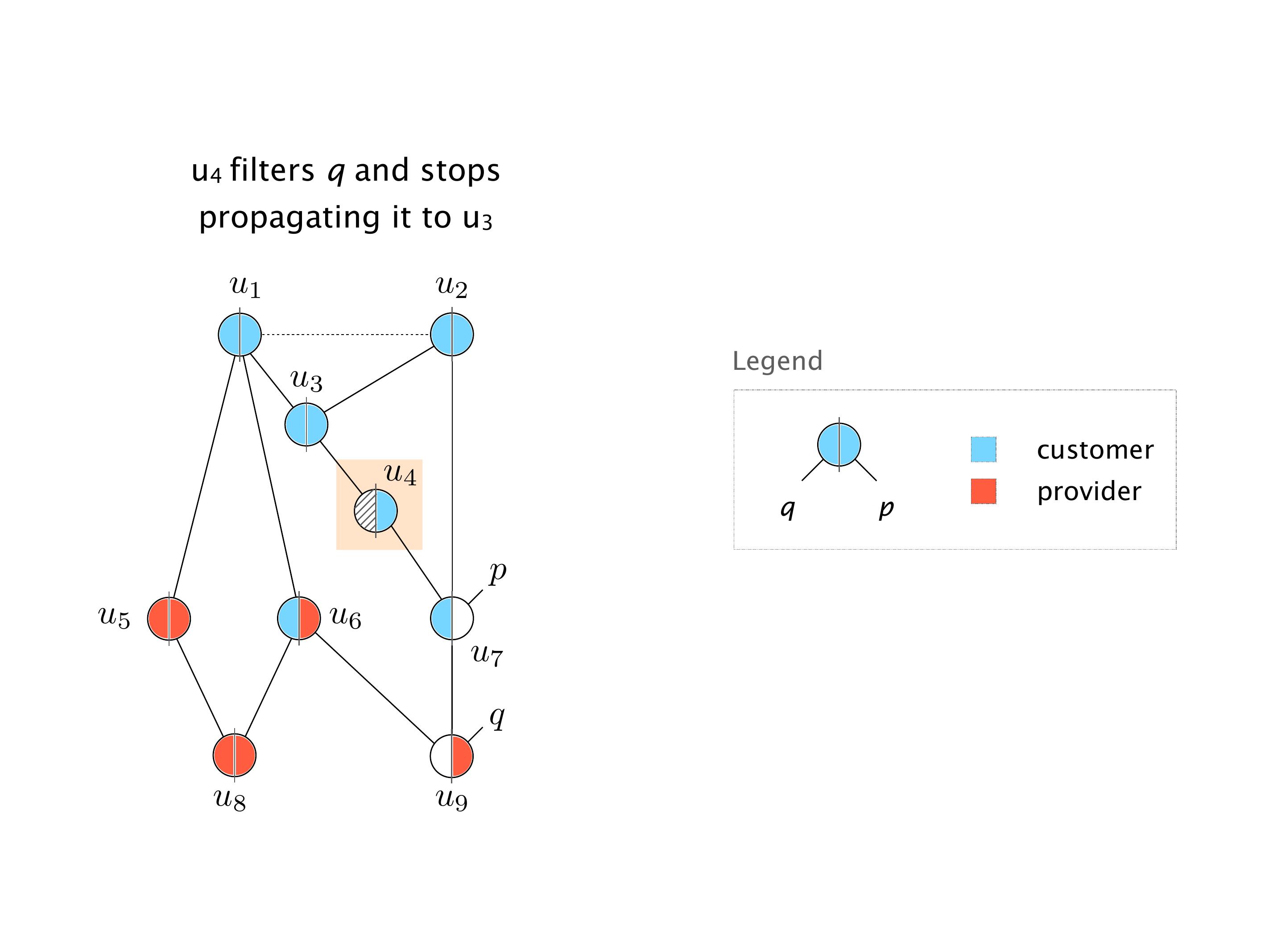
Here you have a topology with three vertices around the bottom. One there is R1, one there is R2, and one there is R3. And then you have three route reflectors. The route reflectors are totally fine. There is a full mesh of peer sessions between tier ones.
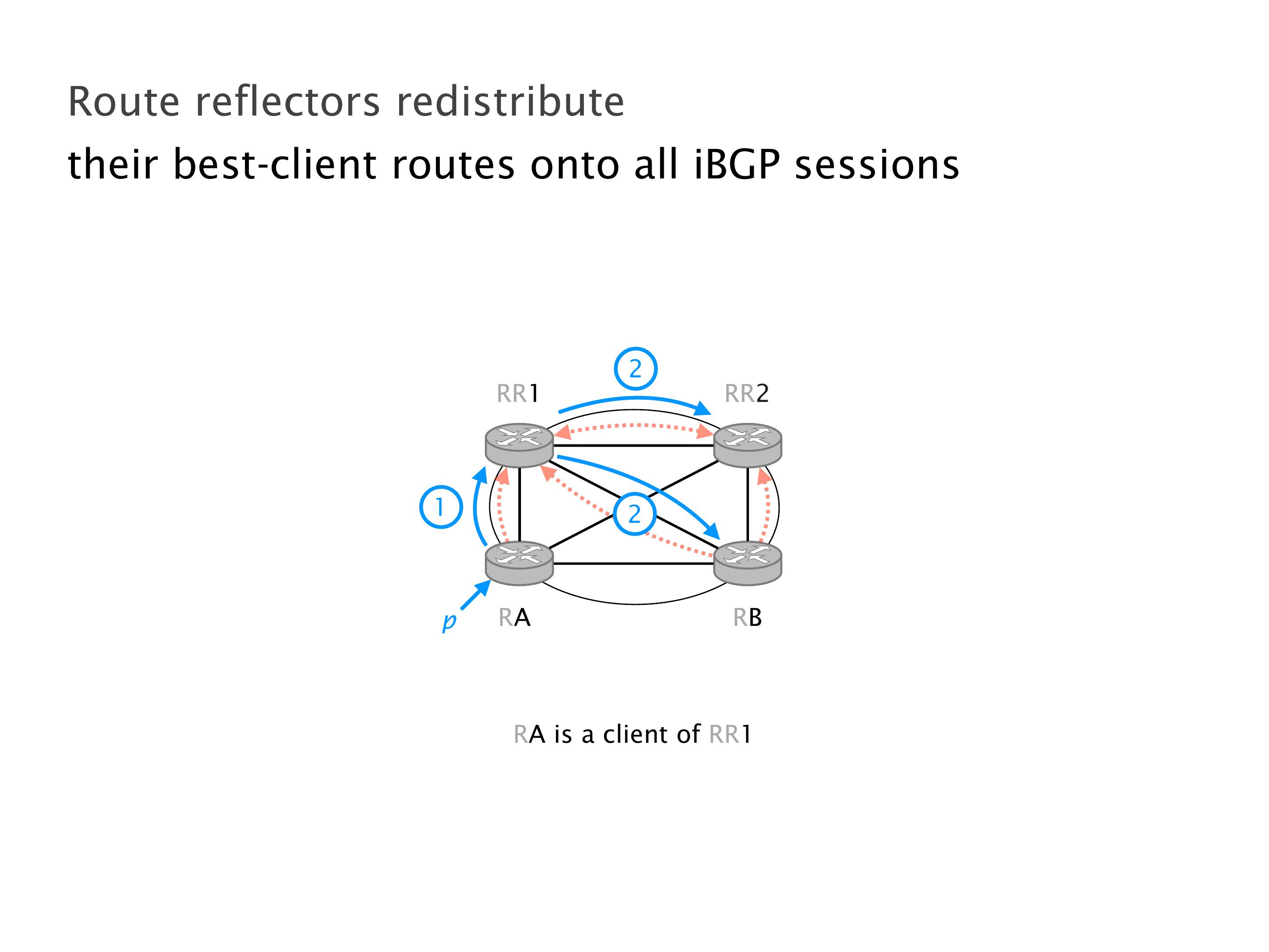
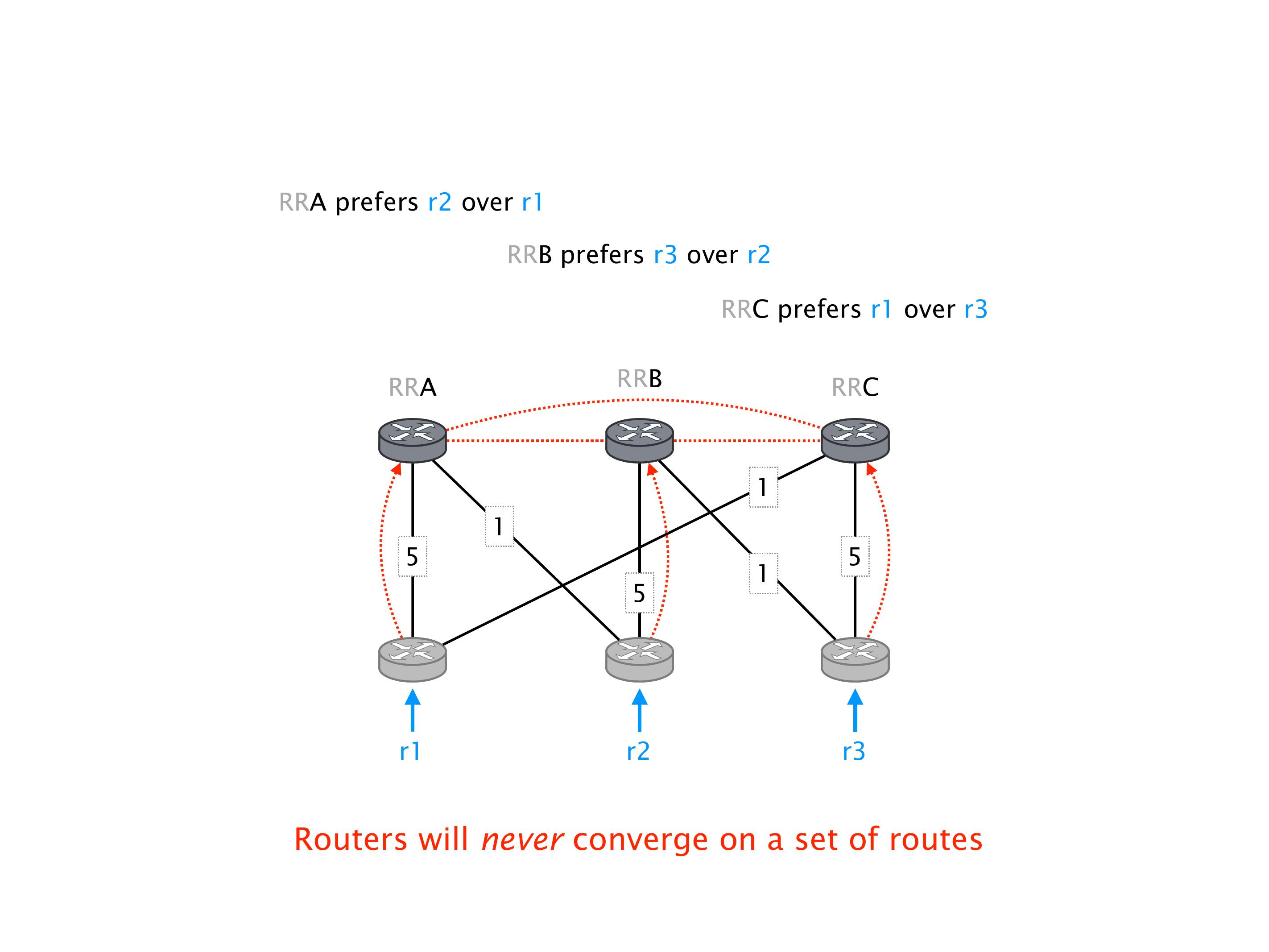
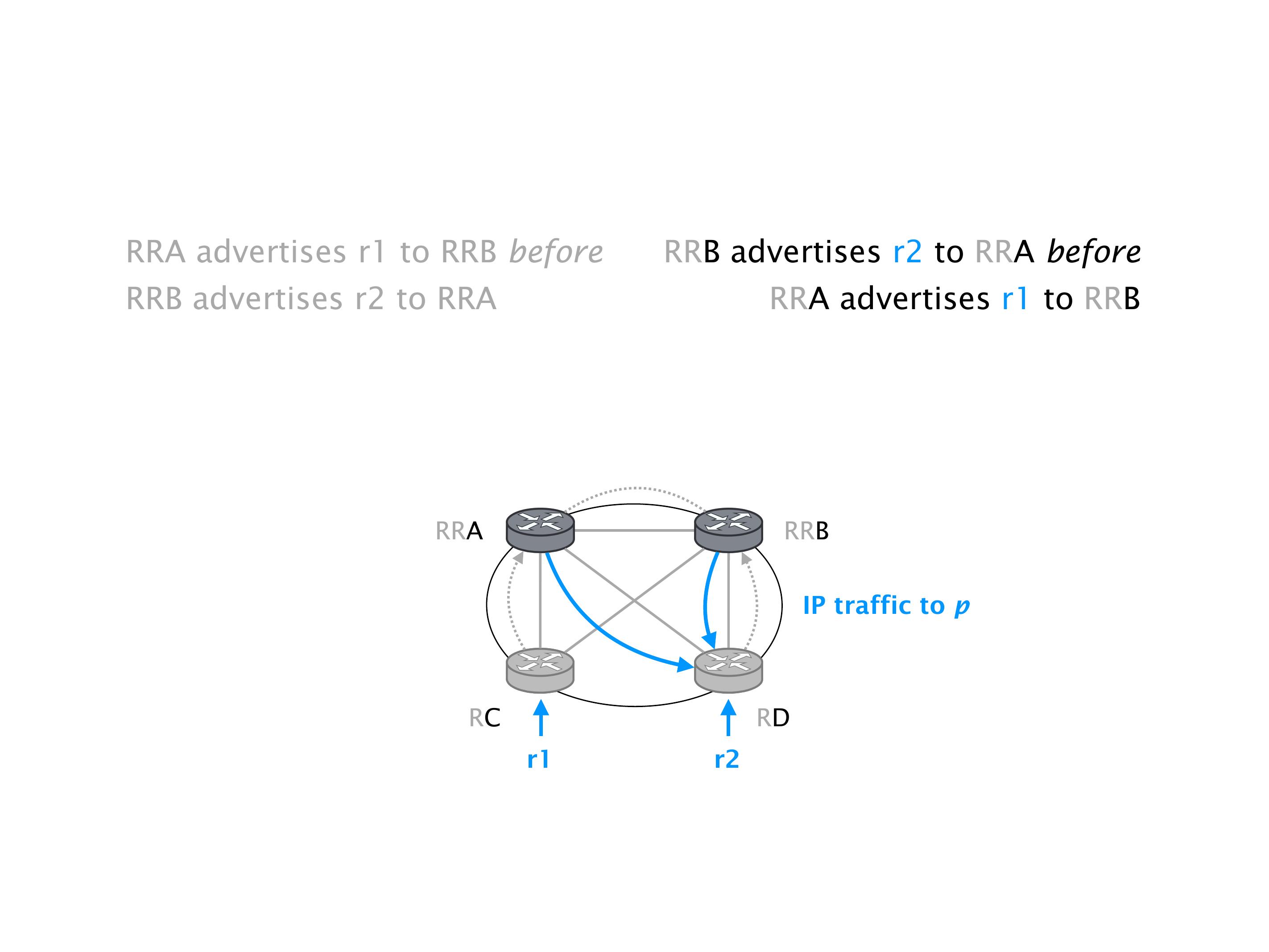
Again, same thing. And then this router is the client of A, this router of B, and then this router is the client of C. But then this is where the weirdness happens. If you look at the preference of A in terms of IGP cost, A is closer to this router than to that router's client. So A prefers R2 over R1.
B is closer to R3 than it is to R2. So B prefers R3 over R2. And then, finally, C prefers R1 over R3. So again, you can see now we have a cyclical relationship here, where each router prefers a router on the right, like a torus kind of thing, where C goes back to A.
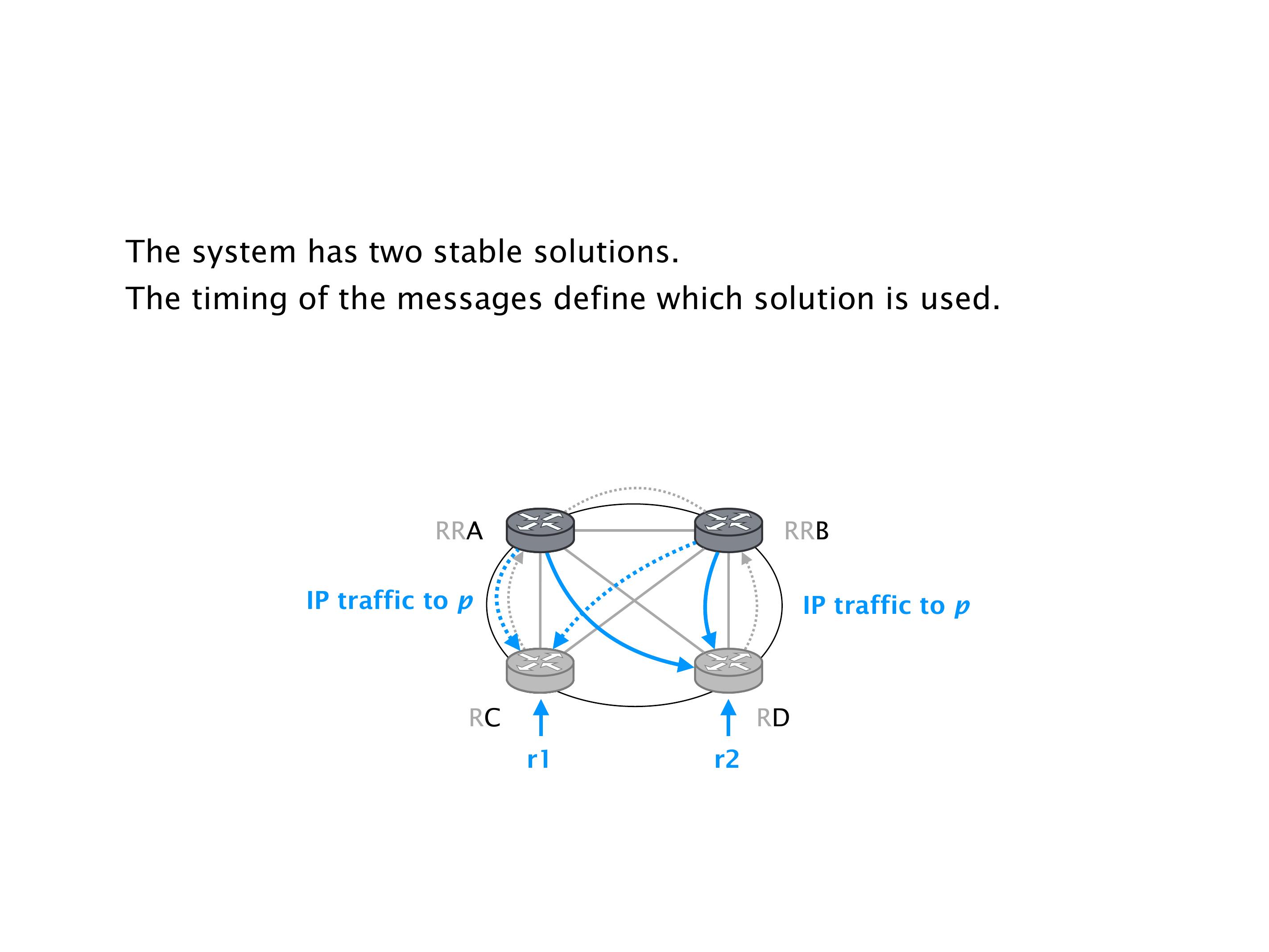
Here, you would do that in the exercises. But this network will never converge. So if you configure this network, again, you can, nothing prevents you from spinning up a virtual network, and then configuring the network like that, you will see that the routers will forever exchange routes. They will never converge.
It doesn't necessarily mean that the traffic will be lost. It just means that sometimes RA will go here, and we send the traffic to R2, sometimes we send it to R1, etc. So the traffic will keep shifting, not necessarily being dropped. You can combine oscillation with the forwarding loops, in which case the oscillation creates the forwarding loops. These are the most extreme cases. But that wouldn't be the case over there.
Still, it's very annoying for traffic to oscillate. Again, if you think about what TCP does, TCP is trying to estimate the delay, the RTT, the round-trip time between the source and the destination. And it needs a little bit of time for that. It needs some packets in order to measure this. So if the paths keep changing, then the estimates of TCP are kind of pointless because the two paths can have drastically different RTT in practice, meaning that the behavior of TCP will continue to shift as well. So we have poor performance. TCP really doesn't like jitter, meaning variance in the RTT. This is why it's bad. And also, you have your router forever doing work, which is useless.